Yogin is Your Own Gin
Go语言已经为我们提供了强大的net/http库,对于初学者而言,可以用几行代码搭建起一个简单的HTTP服务,和浏览器谈笑风生。
 Go语言的网络标准库1
Go语言的网络标准库1
但是,当HTTP服务变得复杂起来后,Go语言自带的库就显得力不从心了,为了实现不同功能,我们会编写大量重复的代码,变得难以维护。因此,基于一个Web框架开发是更好的选择。
Gin是Go语言中一个小而美的框架,提供上下文、路由、中间件、日志、错误恢复、模板等封装,简化了我们的开发流程。本系列文章将带大家从零开始搭建一个类似gin的框架,自底向上地帮助我们理解gin的源码与设计,涵盖gin中的下列关键代码:
gin.gocontext.gotree.goroutegroup.gologger.gorecovery.goauth.go
除此之外,我们会再扩展一些实用的中间件实现:
limit.gosessions.go
作为开篇,我们将首先介绍HTTP服务器的工作流程,然后开始路由树methodTree的建立,最后介绍处理请求的上下文Context。
HTTP服务器的工作流程
HTTP服务器工作在应用层,其面向的客户端主要是浏览器,服务器与客户端之间用HTTP协议通信。因此,对于服务器而言,需要有接收和解析HTTP报文的能力,并根据报文的语义执行相应的逻辑,将执行结果以HTTP报文形式返回给客户端。
利用Go语言提供的net/http包,我们可以用几行代码建立一个HTTP服务器:
1
2
3
4
5
http.Handle("/foo", fooHandler)
http.HandleFunc("/bar", func(w http.ResponseWriter, r *Request) {
// ...
})
log.Fatal(http.ListenAndServe(":8080", nil))
http.Handle和http.HandleFunc可以设置静态路由和对应的处理逻辑,这些逻辑注册到http. DefaultServeMux中。HandleFunc函数会把传入的函数转换为HandlerFunc结构体,该结构体与传入http.Handle的fooHandler一样,都实现了http.Handler接口:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
func Handle(pattern string, handler Handler) { DefaultServeMux.Handle(pattern, handler) }
func HandleFunc(pattern string, handler func(ResponseWriter, *Request)) {
DefaultServeMux.HandleFunc(pattern, handler)
}
func (mux *ServeMux) HandleFunc(pattern string, handler func(ResponseWriter, *Request)) {
if handler == nil {
panic("http: nil handler")
}
mux.Handle(pattern, HandlerFunc(handler))
}
type Handler interface {
ServeHTTP(ResponseWriter, *Request)
}
type HandlerFunc func(ResponseWriter, *Request)
// ServeHTTP calls f(w, r).
func (f HandlerFunc) ServeHTTP(w ResponseWriter, r *Request) {
f(w, r)
}
mux.Handle会将Handler注册到服务器路由表中,以map[string]muxEntry形式存储。
调用http.ListenAndServe函数后,服务器实例会调用net.Listen监听端口,用net.Listener结构的Accept方法获取客户端连接。收到客户端请求后,服务器最终会调用serverHandler服务请求,从ServeMux中匹配路由表,调用对应的Handler。
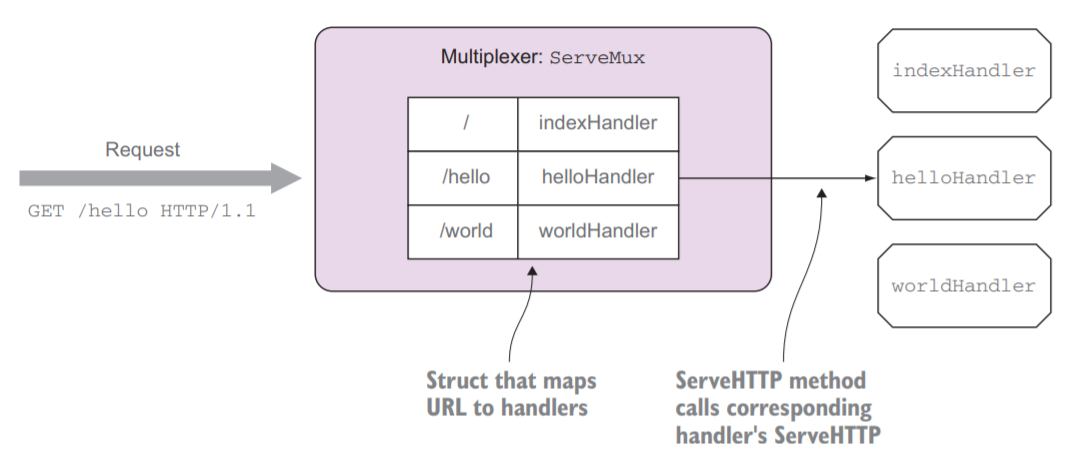 路由规则映射1
路由规则映射1
在开头的示例代码中,我们用http.ListenAndServe(":8080", nil)的方式启动服务器,第二个参数传入nil。此时,服务器会使用DefaultServeMux进行路由匹配,里面记录了我们用http.Handle和http.HandleFunc注册的函数。我们也可以传入一个自己写的实现了http.Handler接口的结构体,接管服务器的行为。
寻找负责人:路由树methodTree
既然接管了服务器处理请求的行为,那么当请求到来后,路由的工作就要交给我们自己了。虽然我们可以借助http.ServeMux提供路由管理能力,但实现一个自己的路由逻辑可以带来更多的好处,例如:
- 分别管理不同的HTTP方法:
ServeMux只提供基本的路由映射,不区分相同URL的不同HTTP方法。在实际项目中,同一个URL的GET和POST的处理逻辑往往是不一样的,因此要分开判断和处理。不同方法的处理逻辑拥挤在同一个函数中会降低代码的可读性。 - 实现动态路由:如果上述特性只是对原有库函数功能的锦上添花,那么动态路由则是一个重要的功能点了。我们希望使用如同
/user/:username、/static/*filepath这样的动态路由,避免静态路由的罗列枚举,并且希望在处理请求时能够得到:username字段的具体参数值。
我们将管理一个methodTrees,这是一个由多个methodTree组成的哈希表,每个methodTree负责管理不同方法的路由:
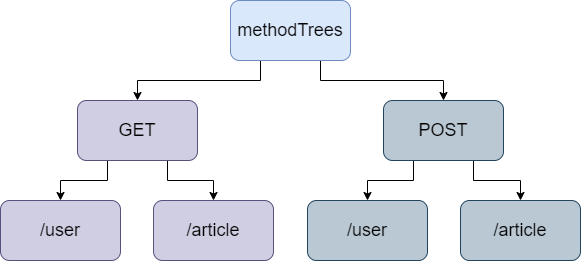 methodTrees
methodTrees
Trie树
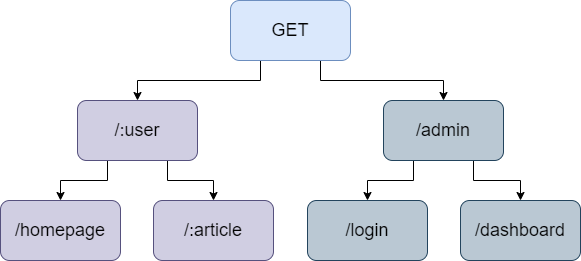 methodTree
methodTree
这棵树主要实现两种方法:插入路由项addRoute和匹配路由项getRoute。
1
2
3
4
5
6
7
8
9
10
11
12
type methodTree struct {
method string
root *node
}
func (t *methodTree) addRoute(path string, handlers HandlersChain) {
// ...
}
func (t *methodTree) getRoute(path string) (value nodeValue) {
// ...
}
在插入路由项时,我们需要将路径分割为多个segment,作为一串节点插入Trie树中。例如,将/:user/:article分为/:user和/:article,逐层插入。若此前已经插入了/:user/homepage,那么/:user会先匹配到/:user/homepage的第一个segment节点,然后检查其子节点,发现还没有/:article子节点项,于是新建一个子节点插入树中。
路由冲突
在新建路由项时,每次都至少在Trie树中新建了一个节点,这在建树时不会遇到什么困难。但是,在之后的路由匹配时,通配符的存在会对路由带来二义性。
例如,路由规则中如果同时在第一个segment处出现了通配符,那么在搜索第一层时会同时匹配到多个节点。在我们的测试用例中,一个典型的例子是路由规则中同时存在/hello/:world、/:hello/world和/:hello/:world时,路径/hello/world应该如何匹配?
在gin中,各层优先匹配字符串字面量,若匹配到,优先选择该节点进入下一层匹配。因此/hello/world先匹配到/hello/:world规则中的hello节点,进入下一层后发现有合适的匹配项/:world,最终选择这条路由。
仅这条规则还不够,用户还可能会在同一层设置不同的通配符表达不同的参数含义,例如下面的例子:
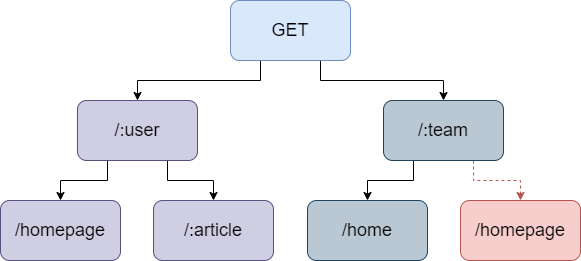 路由冲突
路由冲突
虽然路由表中只存在/:user/homepage和/:team/home这两条规则时,它们是可以相互区分的,但如果稍后加入了/:team/homepage规则,那么面对/yogin/homepage这个URL,我们会匹配到多个路由项,这是不允许的。
为了简化路由实现逻辑,gin从根源上避免了此类冲突,在某个节点的子节点中,最多允许有一个通配符子节点。这个限制也自然地处理了通配符*与:之间的冲突。此外,gin规定*通配符只能出现在路径末尾,不允许/*hello/world这样的规则出现,进一步简化实现逻辑。
为了实现“字符串字面量优先匹配”,gin的代码实现时总是在子节点列表末尾存放通配符节点,为简化代码,yogin对Trie树节点作出如下定义:
1
2
3
4
5
6
7
8
type node struct {
segment string
handlers HandlersChain
children []*node
wildChild *node // at most one :param or *catchAll style child
path string
fullPath string
}
node将子节点分为children和wildChild,children存放字符串字面量,wildChild存放通配符节点。path代表了节点对应的路径前缀,即从根节点到当前节点的路径所表示的URL前缀。fullPath和handlers仅在Trie树的叶节点中设置,表示路由的完整路径及对应的处理逻辑。
插入路由
插入路由项的主体逻辑与普通的Trie树一样,只是要新增检测冲突的逻辑。gin中以迭代形式插入节点。为实现方便,我们以递归形式插入:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
func (t *methodTree) addRoute(path string, handlers HandlersChain) {
segments := parseSegments(path)
t.root.insertChild(segments, 0, path, handlers)
}
func (n *node) insertChild(segments []string, level int, fullPath string, handlers HandlersChain) {
if len(segments) == level {
if n.fullPath != "" {
panic(fmt.Sprintf("new route %s conflicts with existing route %s", fullPath, n.fullPath))
}
n.fullPath = fullPath
n.handlers = handlers
return
}
segment := segments[level]
if isCatchAll(segment) && len(n.children) > 0 {
panic(fmt.Sprintf("catch-all conflicts with existing handle for the path segment root in path %s", fullPath))
}
if isWild(segment) && n.wildChild != nil && n.wildChild.segment != segment {
panic(fmt.Sprintf("%s in new path %s conflicts with existing wildcard %s in existing prefix %s", segment, fullPath, n.wildChild.segment, n.wildChild.path))
}
child := n.matchChild(segment)
isWild := isWild(segment)
// create new node
if child == nil {
child = &node{segment: segment, path: path.Join(n.path, segment)}
if isWild {
n.wildChild = child
} else {
n.children = append(n.children, child)
}
}
if isCatchAll(segment) && level+1 != len(segments) {
panic(fmt.Sprintf("catch-all routes are only allowed at the end of the path %v", fullPath))
}
child.insertChild(segments, level+1, fullPath, handlers)
}
func (n *node) matchChild(segment string) *node {
// let the caller judge if there is conflict
if isCatchAll(segment) || isParam(segment) {
if n.wildChild != nil && n.wildChild.segment != segment {
panic("conflict")
}
return n.wildChild
}
for _, child := range n.children {
if child.segment == segment {
return child
}
}
return nil
}
路由匹配
因为解决了路由二义性问题,我们只需要按照匹配规则进行路由匹配即可。具体而言,我们对Trie树进行深度优先搜索,优先选择字符串字面量节点(即children中的节点),其次再选择wildChild,注意wildChild可能为nil。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
func (t *methodTree) getRoute(path string) (value nodeValue) {
segments := parseSegments(path)
n := t.root.getValue(segments, 0)
if n != nil {
value.handlers = n.handlers
value.fullPath = n.fullPath
patterns := parseSegments(n.fullPath)
value.params = make(Params, 0)
for index, pattern := range patterns {
if pattern[0] == ':' {
value.params = append(value.params, Param{pattern[1:], segments[index]})
} else if pattern[0] == '*' && len(pattern) > 1 {
value.params = append(value.params, Param{pattern[1:], strings.Join(segments[index:], "/")})
}
}
}
return
}
func (n *node) getValue(segments []string, level int) *node {
if len(segments) == level || strings.HasPrefix(n.segment, "*") {
if n.handlers == nil {
return nil
}
return n
}
segment := segments[level]
child := n.matchChildAndWild(segment)
if child == nil {
return nil
}
return child.getValue(segments, level+1)
}
func (n *node) matchChildAndWild(segment string) *node {
for _, child := range n.children {
if child.segment == segment {
return child
}
}
// if no string literal child, return wildChild (which can also be nil)
return n.wildChild
}
在匹配完成后,根据Trie树叶节点提供的fullPath信息,我们可以与用户的请求URL比对,得出蕴含在URL中的参数Param,如/:user的具体值。这些值存放在getRoute的返回值中:
1
2
3
4
5
6
7
8
9
10
11
12
type nodeValue struct {
handlers HandlersChain
params Params
fullPath string
}
type Param struct {
Key string
Value string
}
type Params []Param
路由规则对应的处理函数放在handlers字段中返回,实现了URL到处理逻辑的映射。gin的tree.go实现3比本文要复杂许多,树中的节点有优先级区分,以迭代形式遍历Trie树,性能更好。此外,gin对路由的处理更具有鲁棒性,且会对/user和/user/这样的路由会进行区分处理。当/user/规则不存在时会重定向到/user规则。
多个负责人?
在具体业务中,我们可能希望一个响应有多个Handler,这些Handler各司其职,因此不希望它们的代码耦合在一起。例如,一个Handler负责具体的业务逻辑,而另一个Handler负责API流量统计等业务无关任务。
 多个处理函数1
多个处理函数1
为此,Trie树的叶节点中存放的是HandlersChain类型,方便设置多个处理函数:
1
2
type HandlersChain []HandlerFunc
type HandlerFunc func(*Context)
多个HandlerFunc链式调用,形成一条责任链。接下来我们将讲述如何实现这样的链式调用。
计算的输入与输出:上下文Context
在完成路由功能后,我们就可以来着重看一看如何处理请求了。HTTP服务器处理业务的本质就是从HTTP报文中获取计算的输入,然后返回HTTP响应作为输出。net/http的Handler在其ServeHTTP方法中,有两个参数:w ResponseWriter和r *Request,分别对应输出以及输入。为了方便请求的处理,我们将它们封装为上下文Context,同时提供更多工具函数作为net/http提供的API的补充,进一步简化代码编写。
上下文作为我们框架中所有HandlerFunc的输入参数,意味着其会走完整个请求的处理-应答生命周期。因此,除了记录来自客户端的输入,我们完全可以在上下文中保存来自上游HandlerFunc的计算结果,用于在下游进一步处理。
最后,上下文还可以保存任何HandlerFunc处理过长中的错误信息,框架在处理完请求回收当前上下文时可以打印这次请求处理中发生的错误。上下文的完整设计如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
type Context struct {
Writer http.ResponseWriter
Request *http.Request
// middlewares
handlers HandlersChain
index int8 // current middleware
// request info
Path string
Method string
ClientIP string
Params Params
FullPath string
// response info
statusCode int
bodySize int
// Errors is a list of errors attached to all the handlers/middlewares who used this context.
Errors []error
// This mutex protect Keys map
mu sync.RWMutex
// Keys is a key/value pair exclusively for the context of each request.
Keys map[string]interface{}
engine *Engine
}
来自请求头的输入:GetHeader
该方法是对库函数的简单封装:
1
2
3
4
// GetHeader returns value from request headers.
func (c *Context) GetHeader(key string) string {
return c.Request.Header.Get(key)
}
来自URL的输入:Param与Query
我们可以从请求URL中获取两部分信息,一部分是匹配到动态路由时,URL蕴含的参数值,另一部分是以/path?key1=value1&key2=value2形式传送的键值对。
对于第一种参数,我们在路由匹配时就会完成这部分参数的获取,并将其纳入匹配结果nodeValue类型的返回中。对于第二种参数,我们可以用库函数提供的方法获取。
1
2
3
4
5
6
7
func (c *Context) Param(key string) string {
return c.Params.ByName(key)
}
func (c *Context) Query(key string) string {
return c.Request.URL.Query().Get(key)
}
其中,我们为Params类型封装了ByName方法,方便我们从参数列表中根据参数名找到对应的值:
1
2
3
4
5
6
7
8
9
10
11
12
13
func (ps Params) Get(name string) (string, bool) {
for _, entry := range ps {
if entry.Key == name {
return entry.Value, true
}
}
return "", false
}
func (ps Params) ByName(name string) (va string) {
va, _ = ps.Get(name)
return
}
来自POST请求的输入:PostForm
POST请求的部分输入还会放在请求体中,我们可以用PostForm获得:
1
2
3
func (c *Context) PostForm(key string) string {
return c.Request.FormValue(key)
}
gin的上下文实现4中对URL和POST请求中的参数进行了缓存,使用了下面的两个cache:
1
2
3
4
5
6
// queryCache use url.ParseQuery cached the param query result from c.Request.URL.Query()
queryCache url.Values
// formCache use url.ParseQuery cached PostForm contains the parsed form data from POST, PATCH,
// or PUT body parameters.
formCache url.Values
第一次调用Query和PostForm时会初始化相应的缓存,之后的查询直接返回缓存中的值,而不再调用库函数。
输出:响应头和响应体
我们可以调用http.ResponseWriter提供的方法来设置响应头,支持值的插入和删除:
1
2
3
4
5
6
7
func (c *Context) Header(key, value string) {
if value == "" {
c.Writer.Header().Del(key)
return
}
c.Writer.Header().Set(key, value)
}
我们可以用Status方法设置响应的状态码,注意状态码只能设置一次,若有多个**HandlerFunc**尝试设置状态码,只有第一次有效:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
func (c *Context) Status(code int) {
if code > 0 && c.statusCode != 0 && c.statusCode != code {
c.Error(fmt.Errorf(c.Error(fmt.Errorf("[WARNING] Headers were already written. Wanted to override status code %d with %d, rejected", c.statusCode, code)))
return
}
c.statusCode = code
c.Writer.WriteHeader(code)
}
func (c *Context) OK() *Context {
c.Status(http.StatusOK)
return c
}
func (c *Context) NotFound() *Context {
c.Status(http.StatusNotFound)
return c
}
func (c *Context) Forbidden() *Context {
c.Status(http.StatusForbidden)
return c
}
我们可以封装一些基本函数,方便用户设置响应体:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
var (
jsonContentType = []string{"application/json; charset=utf-8"}
htmlContentType = []string{"text/html; charset=utf-8"}
plainContentType = []string{"text/plain; charset=utf-8"}
)
func (c *Context) WithString(format string, values ...interface{}) *Context {
writeContentType(c.Writer, plainContentType)
data := []byte(fmt.Sprintf(format, values...))
wc, _ := c.Writer.Write(data)
c.bodySize += wc
return c
}
func (c *Context) String(code int, format string, values ...interface{}) {
c.Status(code)
c.WithString(format, values...)
}
func (c *Context) WithJSON(obj interface{}) *Context {
writeContentType(c.Writer, jsonContentType)
data, err := json.Marshal(obj)
if err != nil {
panic(err)
}
wc, _ := c.Writer.Write(data)
c.bodySize += wc
return c
}
func (c *Context) JSON(code int, obj interface{}) {
c.Status(code)
c.WithJSON(obj)
}
func writeContentType(w http.ResponseWriter, value []string) {
header := w.Header()
if val := header["Content-Type"]; len(val) == 0 {
header["Content-Type"] = value
}
}
与gin不同的是,gin中只提供了类似String和JSON这样的方法,用户每次要传入响应的状态码。例如,c.String(http.StatusOK, "response")。我们新增了一些方法,允许用户以链式调用的方式设置响应体,例如,c.OK().WithString("response")。
此外,gin对http.ResponseWriter进行了额外封装,实现了一个自己的ResponseWriter5,这样可以对原生的Writer进行更加细粒度的管理,例如跟踪是否已经设置过状态码、用户已经写入了多少字节等等。额外封装还可以带来更多特性,例如可以引入输出缓存,从而控制何时真正写回响应。为了简化代码,我们直接使用标准库中的http.ResponseWeiter。
控制流转与中间件
谈到责任链模式,我们可以想到用户在设置多个HandlerFunc时,在当前函数处理结束后,调用c.Next()唤起下一个函数进行处理。
我们可以对HandlersChain进一步加强,提供中间件的功能。对于非中间件的处理函数,不调用Next也可以将控制权交出,而对于中间件函数,允许在剩余的HandlerFunc处理结束后,再次返回当前中间件的执行体,处理一些善后工作。
中间件的实现关键在于Next函数的实现。我们在上下文中用index记录当前执行到第几个处理函数,并在for循环中按顺序调用这些函数。允许在任何处理函数中调用Abort,这样接下来的处理函数都不会得到执行。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
const abortIndex int8 = math.MaxInt8 >> 1
func (c *Context) Next() {
c.index++
s := int8(len(c.handlers))
for c.index < s {
c.handlers[c.index](c)
c.index++
}
}
func (c *Context) Abort() {
c.index = abortIndex
}
func (c *Context) AbortWithStatus(code int) {
c.Status(code)
c.Abort()
}
func (c *Context) IsAborted() bool {
return c.index >= abortIndex
}
在中间件处理时,可以用Set和Get方法向上下文中保存和获取处理结果,上下文会携带这些信息进入下一个处理函数。Set函数会对上下文的键值对哈希表进行懒加载。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
func (c *Context) Set(key string, value interface{}) {
c.mu.Lock()
if c.Keys == nil {
c.Keys = make(map[string]interface{})
}
c.Keys[key] = value
c.mu.Unlock()
}
func (c *Context) Get(key string) (value interface{}, exists bool) {
c.mu.RLock()
value, exists = c.Keys[key]
c.mu.RUnlock()
return
}
func (c *Context) MustGet(key string) interface{} {
if value, exists := c.Get(key); exists {
return value
}
panic(fmt.Sprintf("Key %s does not exist in context", key))
}
上下文对象池
在框架执行过程中,每当有一个新的请求进入,就会新建一个Context实例。在请求处理完成后,这个Context就没有用了,会进入等待垃圾回收的阶段。
为了减少垃圾回收的压力,我们可以复用以前的Context,而不需要每次都创建许多短暂存活的Context然后让垃圾回收器频繁回收。
我们定义框架与用户的主要交互对象Engine:
1
2
3
4
type Engine struct {
methodTrees map[string]methodTree
contextPool sync.Pool
}
在新建框架实例时,初始化对象池:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
func New() *Engine {
engine := &Engine{
methodTrees: make(map[string]methodTree),
}
engine.contextPool.New = func() interface{} {
return engine.allocateContext()
}
return engine
}
func (engine *Engine) allocateContext() *Context {
v := make(Params, 0, 4)
return &Context{Params: v, engine: engine}
}
在服务请求时,我们首先尝试用sync.Pool的Get方法从contextPool中获取一个Context,不存在,则会用allocateContext创建一个新的上下文。注意,虽然有了对象池,但池子中的对象仍然可能被回收。
串起所有:实现ServeHTTP
首先,我们实现addRoute方法,这是对Trie树路由的一个简单封装。我们先用method字段找到负责该方法类型的methodTree,若不存在则新建一个。之后,调用它的addRoute方法。
用户可以用addRoute方法向框架中新建路由处理规则(当然,这个方法目前是包级私有的,之后我们会提供新的公共方法),然后调用Run函数开始服务。
在ServeHTTP的实现中,我们首先从对象池中获取上下文,然后调用reset函数,因为之前请求遗留的上下文会保存过时的信息。reset函数会替换掉自己的Writer和Request,并对index这样的参数进行重置。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
func (engine *Engine) addRoute(method, path string, handlers HandlersChain) {
if _, ok := engine.methodTrees[method]; !ok {
engine.methodTrees[method] = methodTree{method, &node{path: "/"}}
}
tree := engine.methodTrees[method]
tree.addRoute(path, handlers)
}
// ServeHTTP conforms to the http.Handler interface.
func (engine *Engine) ServeHTTP(w http.ResponseWriter, req *http.Request) {
method := req.Method
path := req.URL.Path
c := engine.contextPool.Get().(*Context)
c.reset(w, req)
if _, ok := engine.methodTrees[method]; !ok {
c.handlers = HandlersChain{notFoundHandler}
c.Next()
return
}
tree := engine.methodTrees[method]
value := tree.getRoute(path)
if value.handlers == nil {
c.handlers = HandlersChain{notFoundHandler}
c.Next()
return
}
c.handlers = value.handlers
c.Params = value.params
c.FullPath = value.fullPath
c.Next()
engine.contextPool.Put(c)
}
func (engine *Engine) Run(addr string) (err error) {
err = http.ListenAndServe(addr, engine)
return
}
示例
下面给出了一个使用示例,在运行起来后,我们可以用curl -X GET http://localhost:8080/hello/world查看输出:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
r := New()
method:= http.MethodGet
r.addRoute(method, "/", HandlersChain{
func(c *Context) { c.String(http.StatusOK, "%s %s matches %s", c.Method, c.Path, c.FullPath) },
})
r.addRoute(method, "/:hello", HandlersChain{
func(c *Context) { c.OK().WithString("%s %s matches %s", c.Method, c.Path, c.FullPath) },
})
r.addRoute(method, "/:hello/:world", HandlersChain{
func(c *Context) { c.String(http.StatusOK, "%s %s matches %s", c.Method, c.Path, c.FullPath) },
})
r.addRoute(method, "/:hello/:world/*extra", HandlersChain{
func(c *Context) { c.OK().WithString("%s %s matches %s", c.Method, c.Path, c.FullPath) },
})
r.Run(":8080")
在post01_test.go中,我提供了更多测试用例,包括路由冲突和路由匹配相关的用例,感兴趣的读者可以前去查看,使用go test运行。
完整代码仓库

「Yogin」系列全部代码可在我的GitHub代码仓库中查看:Yogin is Your Own Gin
欢迎提出各类宝贵的修改意见和issues,指出其中的错误和不足!
最后,感谢你读到这里,希望我们都有所收获!