
eBPF是近年来新兴的Linux内核技术,用于提供一种安全、友好的Linux内核态程序执行环境。在以前,当我们想扩展内核的功能,或者借助内核提供的能力进一步开发时,通常需要自己编写Linux内核模块(当然,你也可以选择直接修改Linux源码,然后重新编译内核😅)。内核模块的编写门槛较高,不容易调试,且编写出错很容易导致整个内核崩溃。
eBPF的出现从根本上解决了这些问题,赋予了Linux内核新的生机,这项技术被Netflix的性能优化大神Brendan Gregg称作“Superpowers”1。Brendan Gregg将eBPF与JavaScript进行类比,JavaScript的出现让浏览器在鼠标点击、滚动等事件触发时,可以执行响应逻辑,促成了现在让人眼花缭乱的网页应用。
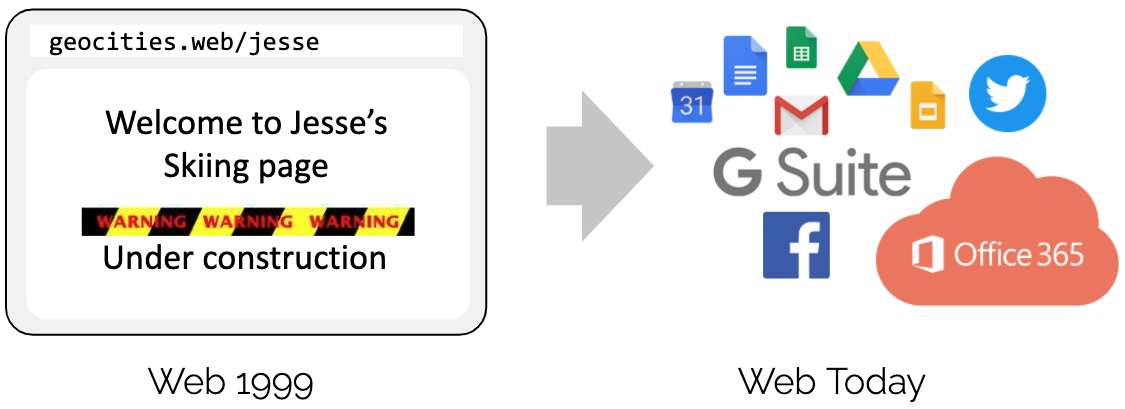 JavaScript给Web网页应用带来巨变2
JavaScript给Web网页应用带来巨变2
类似地,eBPF程序是基于内核事件驱动的,在内核中特定事件发生时,用户编写的eBPF程序会被内核中的eBPF虚拟机执行。eBPF虚拟机会加载eBPF程序的字节码,先由eBPF Verifier验证其安全性,然后解释执行。此外,内核提供了eBPF即时编译功能,可以加速eBPF程序的运行。eBPF的出现给内核带来了可编程性,让人们可以很方便地在Linux运行时动态扩展和丰富内核的能力。内核会确保新增代码逻辑的安全性,且无需重启就可以动态地更改eBPF程序的功能。
历史演进
eBPF的前身是1992年提出的BPF(Berkeley Packet Filter)3,用于在内核中处理和分析网络数据包,可以进行一些统计运算,在内核中执行程序逻辑,过滤与任务无关的数据包。与在用户态分析相比,这种方式能够避免将大量数据包发送到用户态(其中很大一部分是无用的),节省了数据搬运的开销。
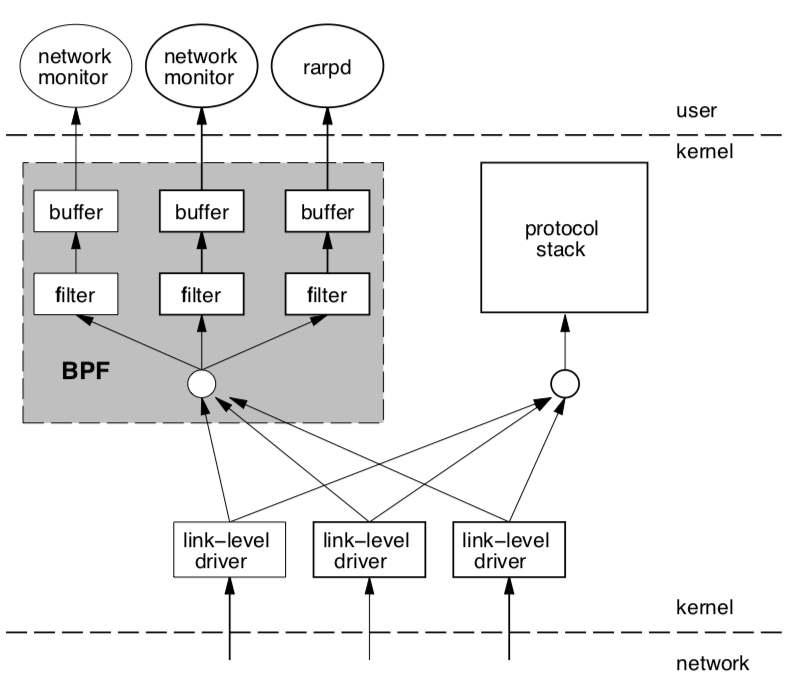 Berkeley Packet Filter3
Berkeley Packet Filter3
从宏观角度来看,eBPF的核心思想与BPF一脉相承。eBPF(extended BPF)在2013年得到扩展,将BPF的能力从网络延伸到内核中更多角落。与BPF相似,eBPF旨在赋予用户编写“Linux内核小程序”的能力,基于事件驱动,让内核处理大部分任务,将结果存入特定数据区域,与用户态共享。
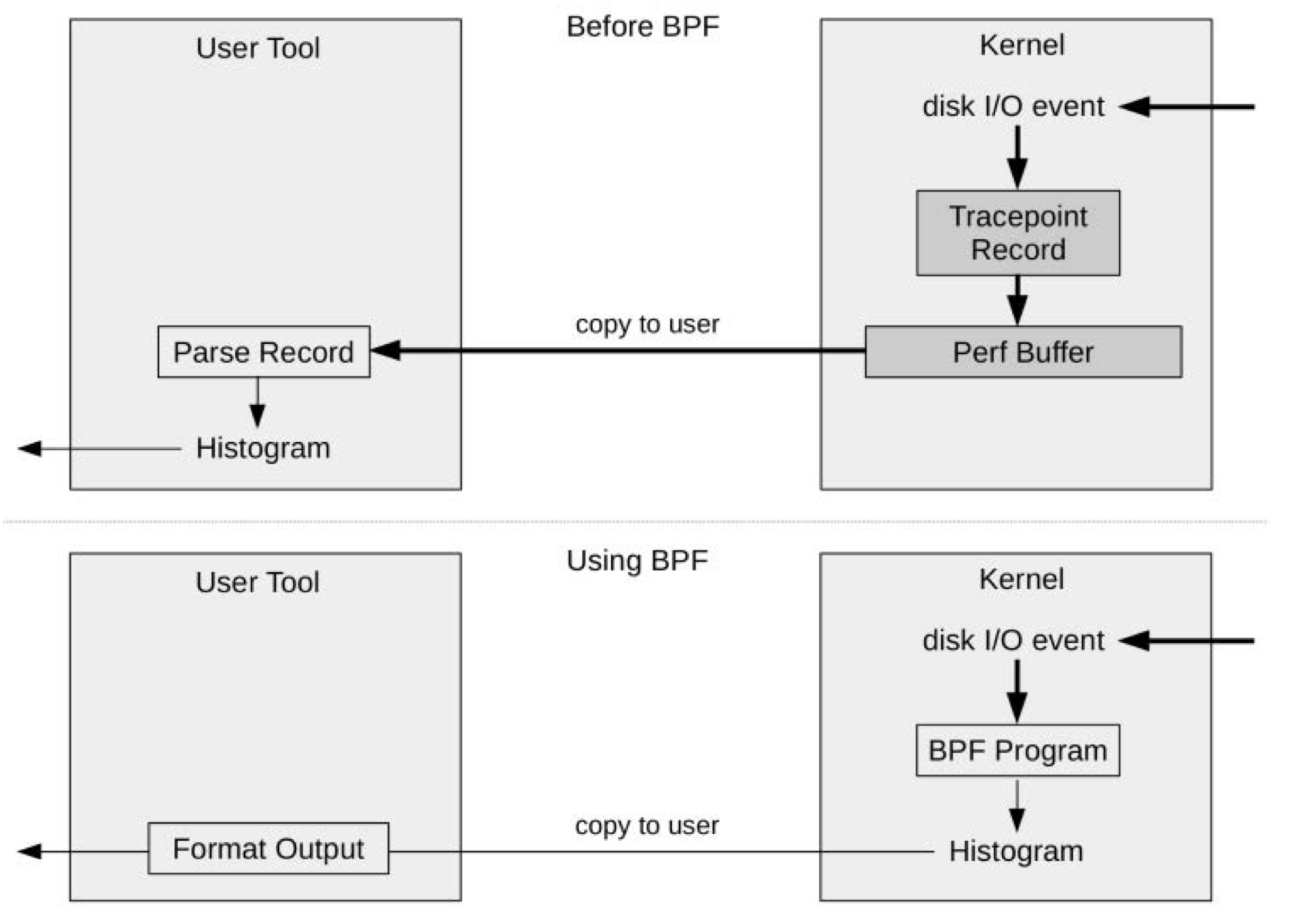 使用eBPF省去大量内核-用户态数据拷贝后,分析处理内核中的事件更高效了4
使用eBPF省去大量内核-用户态数据拷贝后,分析处理内核中的事件更高效了4
使用场景
与内核模块类似,eBPF程序可以在Linux运行时动态地扩展内核的能力,具体涵盖如下方面5:
- 系统安全:监控系统中的系统调用和网络数据包;
- 网络:处理网络数据包;
- 程序跟踪和性能分析:分析程序的执行和调用栈,收集性能分析数据;
- 可观测性和系统监控:在内核中统计系统事件和性能指标。
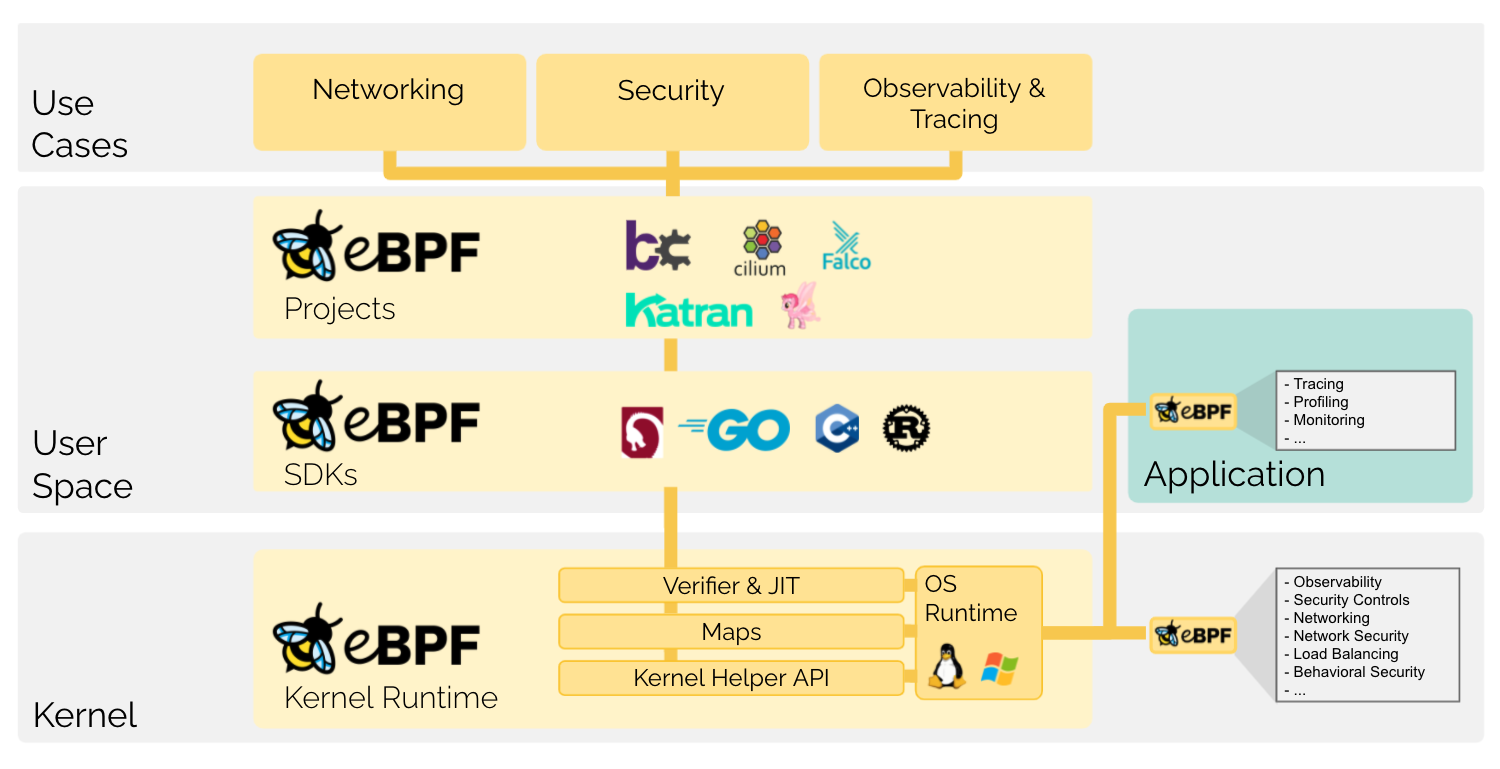 eBPF项目5
eBPF项目5
eBPF程序的生命周期
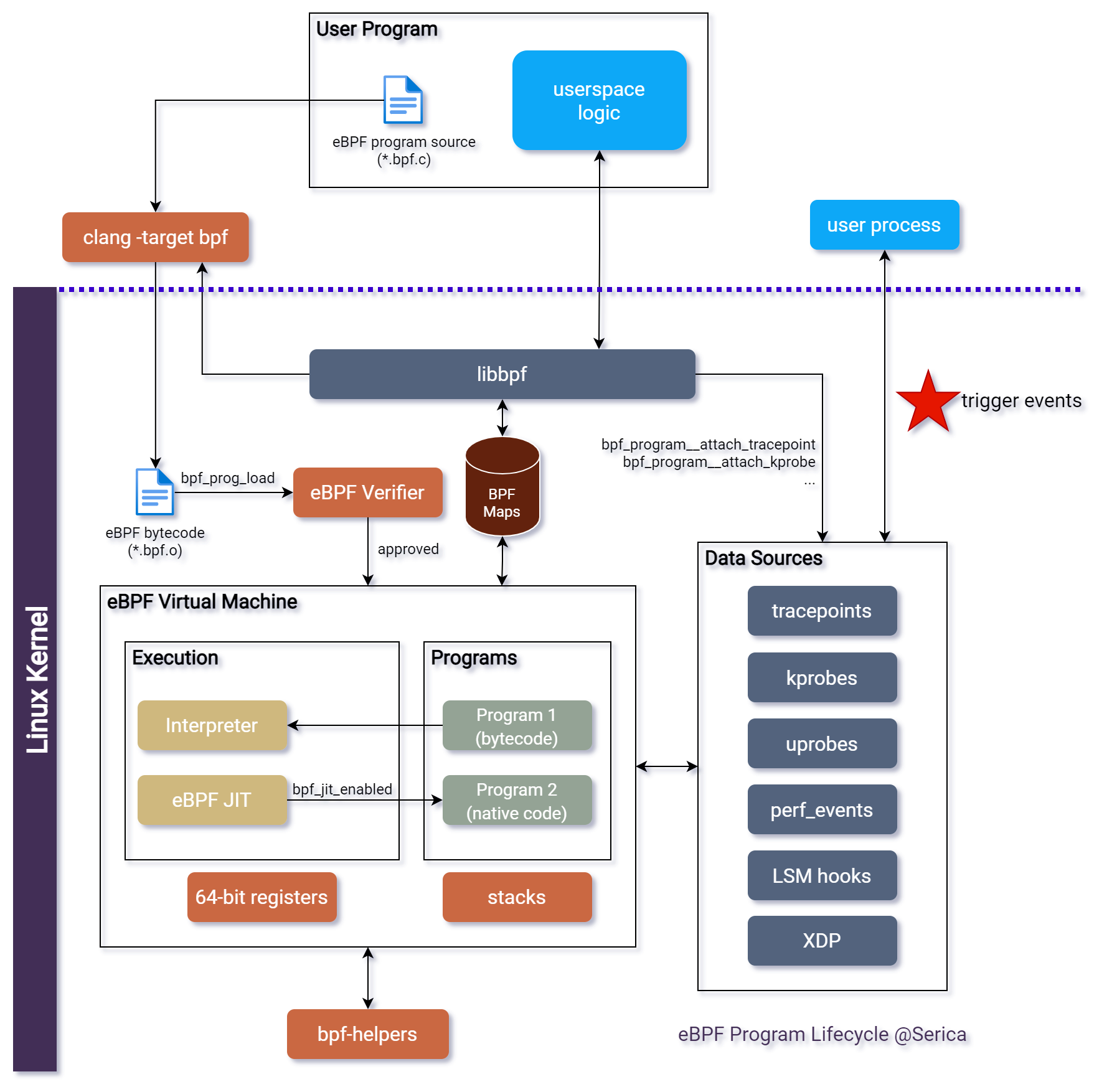 eBPF程序的生命周期
eBPF程序的生命周期
编写和构建
eBPF程序的目标文件是可以被eBPF虚拟机解释执行的eBPF字节码。eBPF有自己的RISC风格指令集,具有运行通用程序的能力,但处于安全性和效率考虑,能在内核中执行的eBPF程序不是图灵完备的。eBPF使用了11个64位寄存器,支持最多512字节的eBPF程序栈6。这个栈空间实际上很小,开一个char[256]大小的数组就已经消耗一半的栈空间了,因此编程时要谨慎考虑如何利用栈空间。对eBPF指令集设计感兴趣的读者可以查看这个由iovisor编写的指令集手册7。
显然,我们可以直接编写eBPF字节码,让Linux内核加载并执行,但这很不友好。因此,我们大可以利用更高层次的抽象,借助LLVM和libbpf库,将C语言程序编译为eBPF字节码。libbpf库是对bpf系统调用8和bpf-helpers9的封装,可用于通知内核加载eBPF字节码、将程序与内核事件关联等等,其代码已经维护在Linux内核源码10中。
除了用C语言写eBPF程序外,eBPF社区还有更高层次的抽象,让我们有方便使用eBPF的能力,例如iovisor维护了bcc11和bpftrace12。bcc11进行了更高层的封装,允许用户开发基于Python和C++编写eBPF程序。作为示例,bcc在其代码仓库中提供了许多实用的性能分析工具bcc-tools13。bpftrace12则提供了一种类似awk的脚本语言,后缀名为.bt,用户使用它的语法可以用几行代码实现一个复杂的eBPF程序。无论是bcc还是bpftrace编写的程序,最终都要先编译为eBPF字节码后才能载入内核。
验证
在加载eBPF程序时,内核会先用eBPF Verifier验证程序的合法性,进行如下检查:
- 检查发起
bpf系统调用8的进程是否具有相应权限,如要求进程具有相关的Linux Capabilities(CAP_BPF)或root权限; - 检查程序是否会导致内核崩溃,例如是否有未初始化的变量,是否有可能导致数组越界、空指针访问的语句,这些边界情况必须显式地在程序中处理,否则即使你确保程序中不会有这些问题,也依然无法通过验证;
- 检查程序是否一定可以执行完,即不允许出现死循环。eBPF只允许有限的循环和跳转,且只允许执行有限的指令条数。
注册和执行
eBPF程序是基于事件驱动的,因此它的运行模式与传统程序的“构建—执行”不同。eBPF程序在完成构建后,需要“挂载”到内核上的对应事件上,当事件产生时,触发内核调用对应的eBPF程序。这点和Web服务端编程有类似。若开启即时编译,内核会把eBPF字节码优化为机器码,使得eBPF程序和内核模块一样高效。
内核提供了多种BPF Maps,包括基于哈希的键值对和数组,在较新的内核中还提供了ring buffer。eBPF程序可以借助这些Map与用户态共享数据,也可以将处理结果保存在这些Map中,供其它eBPF程序使用。借助BPF Maps,可以克服eBPF程序栈空间不足的问题。
eBPF程序在编写时不允许函数调用,即在写C源码时,所有使用到的工具函数在声明时都要加上inline。不过,eBPF提供了一种tail call的方式,允许将函数存放在一个BPF Map中,用bpf_tail_call唤起别的函数。此外,tail call允许嵌套,被唤起的函数也可以调用别的函数,但调用链长度是有限制的。
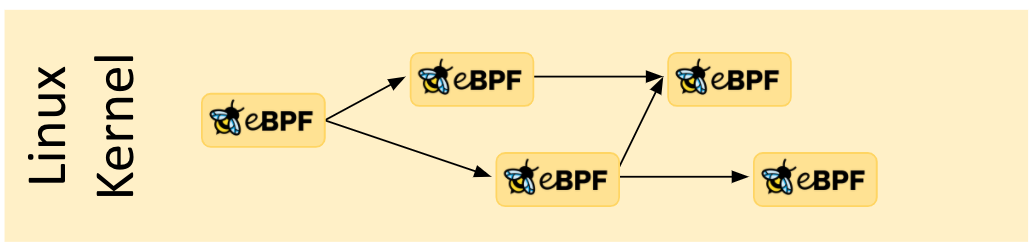 eBPF tail calls5
eBPF tail calls5
eBPF程序被内核调用时,内核会传入一个有限的上下文(context)参数,参数格式取决于不同的事件类型(或eBPF程序类型)。不同的CPU体系结构也有不同的上下文参数,例如寄存器值的含义。在读取上下文中的字段时,可以用内核提供的宏命令来屏蔽不同体系结构的区别,例如PT_REGS_RC。为保证安全性,eBPF程序不能直接访问内核中的内存空间,只有传入的上下文是可以直接读取的,访问其它内存空间需要借助相关的API,如bpf_probe_read,这样可以验证程序身份是否具有访问和修改内核中相关数据结构的能力。
eBPF程序类型
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
enum bpf_prog_type {
BPF_PROG_TYPE_UNSPEC,
BPF_PROG_TYPE_SOCKET_FILTER,
BPF_PROG_TYPE_KPROBE,
BPF_PROG_TYPE_SCHED_CLS,
BPF_PROG_TYPE_SCHED_ACT,
BPF_PROG_TYPE_TRACEPOINT,
BPF_PROG_TYPE_XDP,
BPF_PROG_TYPE_PERF_EVENT,
BPF_PROG_TYPE_CGROUP_SKB,
BPF_PROG_TYPE_CGROUP_SOCK,
BPF_PROG_TYPE_LWT_IN,
BPF_PROG_TYPE_LWT_OUT,
BPF_PROG_TYPE_LWT_XMIT,
BPF_PROG_TYPE_SOCK_OPS,
BPF_PROG_TYPE_SK_SKB,
BPF_PROG_TYPE_CGROUP_DEVICE,
BPF_PROG_TYPE_SK_MSG,
BPF_PROG_TYPE_RAW_TRACEPOINT,
BPF_PROG_TYPE_CGROUP_SOCK_ADDR,
BPF_PROG_TYPE_LWT_SEG6LOCAL,
BPF_PROG_TYPE_LIRC_MODE2,
BPF_PROG_TYPE_SK_REUSEPORT,
BPF_PROG_TYPE_FLOW_DISSECTOR,
BPF_PROG_TYPE_CGROUP_SYSCTL,
BPF_PROG_TYPE_RAW_TRACEPOINT_WRITABLE,
BPF_PROG_TYPE_CGROUP_SOCKOPT,
BPF_PROG_TYPE_TRACING,
BPF_PROG_TYPE_STRUCT_OPS,
BPF_PROG_TYPE_EXT,
BPF_PROG_TYPE_LSM,
BPF_PROG_TYPE_SK_LOOKUP,
BPF_PROG_TYPE_SYSCALL, /* a program that can execute syscalls */
};
常用的包括:
- Tracepoint / raw_tracepoint
- Kprobe / kretprobe / uprobe / uretprobe
- XDP
- Socket Filter
- Perf Event
eBPF Map类型
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
enum bpf_map_type {
BPF_MAP_TYPE_UNSPEC,
BPF_MAP_TYPE_HASH,
BPF_MAP_TYPE_ARRAY,
BPF_MAP_TYPE_PROG_ARRAY,
BPF_MAP_TYPE_PERF_EVENT_ARRAY,
BPF_MAP_TYPE_PERCPU_HASH,
BPF_MAP_TYPE_PERCPU_ARRAY,
BPF_MAP_TYPE_STACK_TRACE,
BPF_MAP_TYPE_CGROUP_ARRAY,
BPF_MAP_TYPE_LRU_HASH,
BPF_MAP_TYPE_LRU_PERCPU_HASH,
BPF_MAP_TYPE_LPM_TRIE,
BPF_MAP_TYPE_ARRAY_OF_MAPS,
BPF_MAP_TYPE_HASH_OF_MAPS,
BPF_MAP_TYPE_DEVMAP,
BPF_MAP_TYPE_SOCKMAP,
BPF_MAP_TYPE_CPUMAP,
BPF_MAP_TYPE_XSKMAP,
BPF_MAP_TYPE_SOCKHASH,
BPF_MAP_TYPE_CGROUP_STORAGE,
BPF_MAP_TYPE_REUSEPORT_SOCKARRAY,
BPF_MAP_TYPE_PERCPU_CGROUP_STORAGE,
BPF_MAP_TYPE_QUEUE,
BPF_MAP_TYPE_STACK,
BPF_MAP_TYPE_SK_STORAGE,
BPF_MAP_TYPE_DEVMAP_HASH,
BPF_MAP_TYPE_STRUCT_OPS,
BPF_MAP_TYPE_RINGBUF,
BPF_MAP_TYPE_INODE_STORAGE,
BPF_MAP_TYPE_TASK_STORAGE,
};
常用的包括:
- Hash / Array:哈希表和数组
- perf_evenrt_array:perf_event ring buffers,可以将数据发送到用户态
- percpu_hash / percpu_array:单个CPU独占的哈希表和数组,性能更好
bpf-helpers
内核不允许eBPF程序直接调用内核中的任意函数,因此只能访问有限的bpf-helpers9。bpf-helpers可以对BPF Maps进行增删改查,部分指令由bpf系统调用8完成。bpf-helpers还包含了内核提供的工具函数,例如读取内核中的内存空间,获取当前时间、打印调试信息等等。常见的函数包括:
- bpf_map_lookup_elem / bpf_map_update_elem / bpf_map_delete_elem:BPF Map操作
- bpf_probe_read / bpf_probe_read_str:读取指向内核空间指针的内容
- bpf_ktime_get_ns:获取时间
- bpf_printk / bpf_trace_printk:打印调试信息
- bpf_get_current_pid_tgid / bpf_get_current_comm / bpf_get_current_task:触发当前事件的进程信息
- bpf_perf_event_output:向perf_event_array写入数据,用于向用户空间发送数据
与内核模块对比
eBPF程序与内核模块的功能类似,接下来我们从不同方面对它们进行比较。
在功能方面:
- 内核模块有几乎全部的内核能力,例如使用内核中的函数以及访问内核中的数据结构;
- eBPF只有有限的bpf-helpers和程序上下文,不能自由调用内核函数和访存;
在分发和部署方式方面:
- 内核模块只能在宿主机上构建和安装,宿主机要有相应的编译和运行环境;
- eBPF程序可以一次构建,多处安装;可以在容器中分发;运行eBPF程序对内核版本有一定要求;
在运行效率方面:
- 内核模块以native code形式运行
- eBPF有虚拟机解释字节码的开销,但也可以开启JIT获得与native code一样的性能
在安全性方面:
- 内核模块的bug容易让内核崩溃或引入安全隐患
- 由于eBPF Verifier的存在,eBPF程序很安全,不会让内核崩溃
在开发友好度方面:
- 开发内核模块门槛较高,不易调试;
- eBPF程序开发环境更友好,提供了丰富的数据结构(BPF Maps);eBPF程序更容易上手和调试。
总结
本文简单介绍了eBPF这一Linux内核中的新兴技术,阐述了eBPF程序的生命周期、程序类型等等。这些介绍基于笔者目前的认识和理解,不保证其正确性。目前eBPF社区十分活跃,有关eBPF的编程知识技巧和使用场景不是三言两语就能说完的。有兴趣的读者可以进一步阅读本文的参考链接。此外,eBPF的官网中展示了eBPF的开发进展、罗列了许多eBPF的项目以及大牛的演讲,介绍了他们在工程实践中是如何使用eBPF技术的。
扩展阅读
- A thorough introduction to eBPF
- BPF Internals (Slides)
- Adrian Ratiu的系列博文
- Greg Marsden的系列博文
- The art of writing eBPF programs: a primer
- Dive into BPF: a list of reading material