
我们已经对eBPF和常见的Linux内核跟踪机制有了一定了解,接下来我们可以整合已有的知识,实现一个简易的进程“监控”程序。在这篇文章中,我们将借助eBPF记录进程的execve和execveat事件,看看系统中的进程在私底下执行了哪些程序。我们首先编写eBPF程序,实现exec事件的探针函数。然后基于libbpfgo编写用户态程序,接受并处理eBPF程序的输出。
这个程序的最终效果如下:
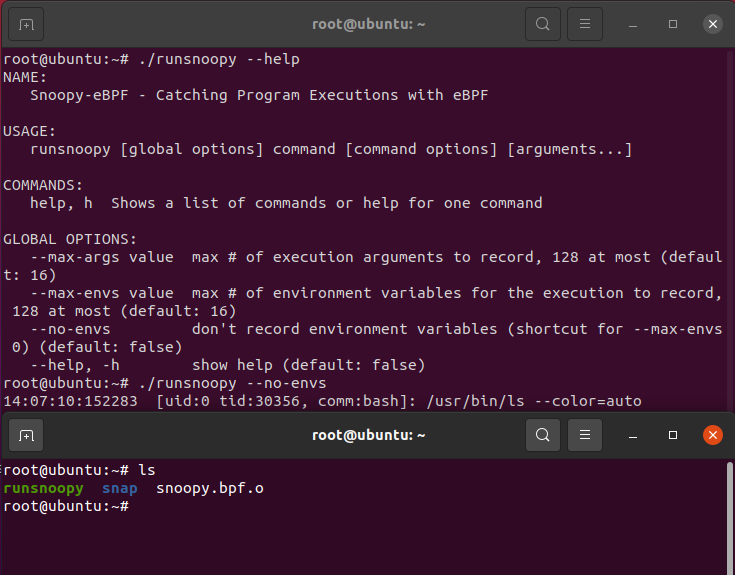
当我们在终端里输入ls命令后,监控程序打印出了这次执行的上下文和参数信息。
编写eBPF程序
定义BPF Maps
我们可以用bpf_create_map在运行时创建一个Map,传入Map的类型、键值的类型以及存放的元素数量:
1
2
int fd, key, value;
fd = bpf_create_map(BPF_MAP_TYPE_HASH, sizeof(key), sizeof(value), 100)
返回的fd可以用于操作BPF Map,例如用bpf_map_update_elem修改元素。通常,在设计程序时我们往往已经想好了要用哪些Map,所以可以在程序里预先定义好。libbpf提供了bpf_map_def结构体,我们可以按照如下惯例来定义BPF Map:
1
2
3
4
5
6
struct bpf_map_def SEC("maps") map_name = {
.type = BPF_MAP_TYPE_HASH,
.key_size = sizeof(int),
.value_size = sizeof(int),
.max_entries = 100,
};
SEC是libbpf提供的宏,用于告知编译器将该结构放在eBPF目标程序ELF文件的map section中,这样程序被加载时根据分区名就可以找到它包含哪些BPF Map。
程序加载完成后,我们可以用libbpf提供的bpf_object__find_map_by_nameAPI获取BPF Map实例,用bpf_map__fd函数获取Map的fd,这样就可以用fd对其增删改查了:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
/**
* @brief **bpf_object__find_map_by_name()** returns BPF map of
* the given name, if it exists within the passed BPF object
* @param obj BPF object
* @param name name of the BPF map
* @return BPF map instance, if such map exists within the BPF object;
* or NULL otherwise.
*/
LIBBPF_API struct bpf_map *
bpf_object__find_map_by_name(const struct bpf_object *obj, const char *name);
/**
* @brief **bpf_map__fd()** gets the file descriptor of the passed
* BPF map
* @param map the BPF map instance
* @return the file descriptor; or -EINVAL in case of an error
*/
LIBBPF_API int bpf_map__fd(const struct bpf_map *map);
可以预见,每当我们要用到一个新的BPF Map时,就要定义一个struct bpf_map_def类型的变量并传入Map的类型等参数。为了减少代码量,我们可以定义如下的宏:
1
2
3
4
5
6
7
8
9
10
11
12
13
#define BPF_MAP(_name, _type, _key_type, _value_type, _max_entries) \
struct bpf_map_def SEC("maps") _name = { \
.type = _type, \
.key_size = sizeof(_key_type), \
.value_size = sizeof(_value_type), \
.max_entries = _max_entries, \
};
#define BPF_HASH(_name, _key_type, _value_type) \
BPF_MAP(_name, BPF_MAP_TYPE_HASH, _key_type, _value_type, 10240)
#define BPF_PERF_OUTPUT(_name) \
BPF_MAP(_name, BPF_MAP_TYPE_PERF_EVENT_ARRAY, int, u32, 1024)
接下来,我们就可以用如下方式声明我们要使用的BPF Map:
1
2
3
BPF_PERF_OUTPUT(execve_out)
BPF_PERF_OUTPUT(execveat_out)
BPF_HASH(config_map, u32, u32)
其中,前两个Map用于向用户态程序输出事件,后一个Map用于读取用户态传来的参数设置。
定义消息格式
有了BPF Map,我们就可以与用户态通信了。首先,对于往用户态输出的消息,我们定义如下格式:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
#define DATA_ARG 0
#define DATA_ENV 1
#define DATA_RET 2
typedef struct event_data {
u64 ts;
u32 type;
u32 pid;
u32 tid;
u32 uid;
s64 ret;
char comm[TASK_COMM_LEN];
char payload[MAX_STRING_SIZE];
} event_data_t;
我们的eBPF程序一共会输出3种类型的数据:进程执行exec时的参数、环境变量以及exec退出时的返回值。具体而言,进程的一次exec操作在调用时会传入若干的参数,调用时会有若干环境变量;exec在返回时会有1次返回值输出。参数和返回值的捕获对应于不同的探针函数,分别挂在到sys_enter_*和sys_exit_*事件上。为了方便起见,我们每解析一个exec的参数就发送一次event_data,在用户层重新将这些参数组装起来。当然,这会导致我们发送了很多冗余数据,如event_data中的pid、comm等字段。一种更好的做法是再在eBPF程序中声明一个数组类型的BPF Map,用于缓存捕获到的参数,然后批量发送给用户态程序。使用BPF Map而不使用一个更大的结构体的原因是因为结构体大小很可能会超过eBPF程序栈的空间限制,因此只能存储在BPF Map中。不过,这种方式对数据编码和解码提出了要求,因为涉及到多个变长的字符串解析。
对于用户态传入的参数配置,我们可以编写一个函数来获取需要的参数,用到了bpf_map_lookup_elem:
1
2
3
4
5
6
7
8
9
10
#define CONFIG_MAX_ARG 0
#define CONFIG_MAX_ENV 1
static __always_inline int get_config(u32 key) {
u32 *config = bpf_map_lookup_elem(&config_map, &key);
if (config == NULL)
return 0;
return *config;
}
在我们的程序中,只用到了两个参数。CONFIG_MAX_ARG表示最多捕获的exec参数数量,CONFIG_MAX_ENV则对应环境变量的数量。
探针函数的上下文参数
编写探针函数时,我们也要按照eBPF程序的分区惯例。例如,对于使用Tracepoint的探针,分区名为tracepoint/subsystem/eventname:
1
2
3
4
SEC("tracepoint/syscalls/sys_enter_execve")
int tracepoint__sys_enter_execve(struct sys_enter_execve_args *ctx) {
// ...
}
这里,我们可以回忆起eBPF程序的参数是一个与事件类型有关的上下文ctx,只有ctx里的字段是可以随意访问的,其它内核地址中的数据都需要用bpf_probe_read这样的bpf-helpers来读取。如何知道ctx的格式呢?这里我们可以参考官方的一些样例:
1
2
3
4
5
6
7
struct syscalls_enter_open_args {
unsigned long long unused;
long syscall_nr;
long filename_ptr;
long flags;
long mode;
};
对于sys_enter_open事件,ctx参数格式如上。我们可以与tracefs中的format对照:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
$ cat /sys/kernel/debug/tracing/events/syscalls/sys_enter_open/format
name: sys_enter_open
ID: 631
format:
field:unsigned short common_type; offset:0; size:2; signed:0;
field:unsigned char common_flags; offset:2; size:1; signed:0;
field:unsigned char common_preempt_count; offset:3; size:1; signed:0;
field:int common_pid; offset:4; size:4; signed:1;
field:int __syscall_nr; offset:8; size:4; signed:1;
field:const char * filename; offset:16; size:8; signed:0;
field:int flags; offset:24; size:8; signed:0;
field:umode_t mode; offset:32; size:8; signed:0;
print fmt: "filename: 0x%08lx, flags: 0x%08lx, mode: 0x%08lx", ((unsigned long)(REC->filename)), ((unsigned long)(REC->flags)), ((unsigned long)(REC->mode))
对于sys_enter_*事件,前8个字节通常用不到,之后8个字节通常是系统调用号,再往后就是Tracepoint中记录的系统调用的参数了。
类似地,我们可以写出本文要用到的上下文参数的格式:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
struct sys_enter_execve_args {
unsigned long long unused;
long syscall_nr;
long filename; // const char *
long argv; // const char *const *
long envp; // const char *const *
};
struct sys_enter_execveat_args {
unsigned long long unused;
long syscall_nr;
long fd;
long filename;
long argv;
long envp;
};
struct sys_exit_args {
unsigned long long unused;
long syscall_nr;
long ret;
};
初始化消息的上下文
也许你还记得,在我们跟踪内核事件时,消息中有两种类型的数据:事件的上下文(context)和负载(payload)。上下文通常是一些通用的信息,例如进程号、进程名、时间戳等,而负载则与事件类型有关,如事件的参数。
我们的event_data中有一些字段表示事件的上下文,我们可以用bpf-helpers来初始化:
1
2
3
4
5
6
7
8
static __always_inline void init_context(event_data_t *data) {
data->ts = bpf_ktime_get_ns();
u64 id = bpf_get_current_pid_tgid();
data->tid = id;
data->pid = id >> 32;
data->uid = bpf_get_current_uid_gid();
bpf_get_current_comm(&data->comm, sizeof(data->comm));
}
记录事件参数
在获取一些基本信息后,我们终于可以来读取exec事件的参数了。根据事件的format,这里的filename字段类型为const char *,指向内核中的地址空间,eBPF程序不能直接读取。因此,我们要使用bpf_probe_read_str函数,传入dst和src指针,以及最多读取的长度MAX_STRING_SIZE。之后,我们立刻调用一次bpf_perf_event_output向用户态输出,因为此时我们已经完成了一条DATA_ARG类型的消息生成。在输出时,我们将没有用到的payload部分截断,实际上只输出了sizeof(data) - sizeof(data.payload) + size字节。
接下来,我们在for循环中遍历exec的参数argv,这是一个字符串数组。每读取一个参数,就向用户态输出一条消息。当参数读完或达到max_arg后停止读取。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
SEC("tracepoint/syscalls/sys_enter_execve")
int tracepoint__sys_enter_execve(struct sys_enter_execve_args *ctx) {
event_data_t data = {};
data.type = DATA_ARG;
init_context(&data);
const char *filename = ctx->filename;
if (!filename) {
return -1;
}
int size = bpf_probe_read_str(&data.payload, MAX_STRING_SIZE, filename);
if (size > 0) {
bpf_perf_event_output(ctx, &execve_out, BPF_F_CURRENT_CPU, &data, sizeof(data) - sizeof(data.payload) + size);
} else {
return -1;
}
const char *const * argv = ctx->argv;
u32 max_arg = get_config(CONFIG_MAX_ARG);
#pragma unroll
for (int i = 1; i < max_arg && i < MAX_LOOP; i++) {
const char *argp = NULL;
bpf_probe_read(&argp, sizeof(argp), &argv[i]);
if (!argp) {
break;
}
int size = bpf_probe_read_str(&data.payload, MAX_STRING_SIZE, argp);
if (size > 0) {
bpf_perf_event_output(ctx, &execve_out, BPF_F_CURRENT_CPU, &data, sizeof(data) - sizeof(data.payload) + size);
} else {
break;
}
}
// ...
return 0;
}
对于环境变量的读取也是类似的,这里不再赘述。
编写用户态程序
libbpfgo
在介绍eBPF时,我们已经知道libbpf库可以帮助我们与eBPF交互,例如借助它来让eBPF虚拟机加载我们编写的eBPF程序,以及读写BPF Maps等等。然而,libbpf是C语言编写的,这在我们编写C语言形式的eBPF程序时并没有什么问题。但与之配套的用户态程序可能是其它语言编写的,例如golang、Python等等。此时,如何调用libbpf库呢?
iovisor的bcc提供了Python的libbpf调用接口,实际上它的bcc-tools大都是Python编写的。此外,iovisor还提供了gobpf,让golang程序也可以调用libbpf,使用方式与基于Python的eBPF程序类似。
然而,这类封装都有一个问题,那就是使用这类封装的程序在运行时都要现场编译eBPF程序,且之后每次启动都要重新编译,效率低下。同时,这给软件分发带来了不便,因为要求运行该程序的机器上安装了bcc,无法做到交叉编译。
libbpfgo项目解决了这一痛点,利用CGo直接与libbpf库交互,向上提供调用接口。项目构建时,只需要将eBPF程序编译一次即可,无须在程序运行时现场编译。
初始化eBPF程序
我们将我们的应用抽象为如下的结构体,包含与eBPF程序状态管理、输出管理有关的字段。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
type Snoopy struct {
bpfModule *bpf.Module
configMap *bpf.BPFMap
config Config
printEnv bool
execveDataChan chan []byte
lostExecveChan chan uint64
execvePerfMap *bpf.PerfBuffer
execveatDataChan chan[]byte
lostExecveatChan chan uint64
execveatPerfMap *bpf.PerfBuffer
eventsChanOut chan *Event
}
接下来,我们编写eBPF初始化的逻辑。首先,调用libbpfgo的NewModuleFromFile打开编译好的eBPF目标程序(*.bpf.o)。该函数会初始化一个bpf_object_open_opts的C语言结构体,将其传入libbpf的bpf_object__open_file API,这个API会返回一个抽象的eBPF程序描述bpf_object,里面记录了eBPF程序的元信息,例如程序的LICENSE、程序名、以及使用的BPF Maps和探针函数等等。
1
2
3
4
5
func New(config Config) (*Snoopy, error) {
// ...
if s.bpfModule, err = bpf.NewModuleFromFile("snoopy.bpf.o"); err != nil {
return nil, err
}
按照eBPF程序的生命周期,在完成open后,load该程序,将其传入eBPF Verifier验证,通过后加载进eBPF虚拟机。我们用到libbpfgo的BPFLoadObject,该函数会调用libbpf的bpf_object__load API。
1
2
3
if err = s.bpfModule.BPFLoadObject(); err != nil {
return nil, err
}
通过eBPF Verifier后,意味着我们编写的eBPF程序没有太大的问题,接下来我们可以传入用户的参数了:
1
2
3
4
5
6
7
8
9
10
11
12
s.configMap, err = s.bpfModule.GetMap("config_map") // u32, u32
// populate configs
configMaxArg := uint32(ConfigMaxArg)
maxArg := uint32(s.config.MaxArg)
configMaxEnv := uint32(ConfigMaxEnv)
maxEnv := uint32(s.config.MaxEnv)
if err = s.configMap.Update(unsafe.Pointer(&configMaxArg), unsafe.Pointer(&maxArg)); err != nil {
return nil, err
}
if err = s.configMap.Update(unsafe.Pointer(&configMaxEnv), unsafe.Pointer(&maxEnv)); err != nil {
return nil, err
}
最后,我们终于可以挂载探针函数了:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
// attach tracepoints
probes := []probe{
{"syscalls:sys_enter_execve", "tracepoint__sys_enter_execve"},
{"syscalls:sys_exit_execve", "tracepoint__sys_exit_execve"},
{"syscalls:sys_enter_execveat", "tracepoint__sys_enter_execveat"},
{"syscalls:sys_exit_execveat", "tracepoint__sys_exit_execveat"},
}
for _, p := range probes {
var prog *bpf.BPFProg
if prog, err = s.bpfModule.GetProgram(p.ProgName); err != nil {
return nil, err
}
if _, err = prog.AttachTracepoint(p.TracePoint); err != nil {
return nil, err
}
}
s.lostExecveChan = make(chan uint64)
s.execveDataChan = make(chan []byte, 300)
s.execvePerfMap, err = s.bpfModule.InitPerfBuf("execve_out", s.execveDataChan, s.lostExecveChan, 1024)
这里调用了libbpf的bpf_object__find_program_by_name和bpf_program__attach_tracepoint等接口。
eBPF程序的输出会存放到perf_event_array中,libbpf允许我们设置一个回调函数,在初始化perf_event_array时传入,当有消息存入时调用该回调函数。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
/**
* @brief **perf_buffer__new()** creates BPF perfbuf manager for a specified
* BPF_PERF_EVENT_ARRAY map
* @param map_fd FD of BPF_PERF_EVENT_ARRAY BPF map that will be used by BPF
* code to send data over to user-space
* @param page_cnt number of memory pages allocated for each per-CPU buffer
* @param sample_cb function called on each received data record
* @param lost_cb function called when record loss has occurred
* @param ctx user-provided extra context passed into *sample_cb* and *lost_cb*
* @return a new instance of struct perf_buffer on success, NULL on error with
* *errno* containing an error code
*/
LIBBPF_API struct perf_buffer *
perf_buffer__new(int map_fd, size_t page_cnt,
perf_buffer_sample_fn sample_cb, perf_buffer_lost_fn lost_cb, void *ctx,
const struct perf_buffer_opts *opts);
libbpfgo在InitPerfBuf时传入了如下的回调函数:
1
2
3
4
func perfCallback(ctx unsafe.Pointer, cpu C.int, data unsafe.Pointer, size C.int) {
pb := eventChannels.Get(uint(uintptr(ctx))).(*PerfBuffer)
pb.eventsChan <- C.GoBytes(data, size)
}
因此,在初始化完成后,我们可以从s.execveDataChan这个channel中读取来自eBPF程序的消息。
处理eBPF程序的消息
接下来,我们要将零散的消息组装,恢复其语义。我们建立一个events表,按照进程的tid存放处理结果Event,这个结构体也是我们最终向用户输出的数据。
根据不同的消息类型,我们进入不同的处理逻辑。首先读取消息中定长的context部分,剩余的即为变长的字符串字段payload。然后,根据消息类型,将其附加到Event的Args或Envs字段中。当收到Ret类型的消息时,此条Event处理完成。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
type context struct {
Ts uint64
Type uint32
Pid uint32
Tid uint32
Uid uint32
Ret int64
Comm [16]byte
}
type Event struct {
Ts uint64
Pid uint32
Tid uint32
Uid uint32
Ret int64
Comm string
Args []string
Envs []string
}
func (s *Snoopy) handler(input <-chan []byte, done <-chan struct{}) {
events := make(map[uint32]*Event)
for rawData := range input {
dataBuff := bytes.NewBuffer(rawData)
var ctx context
err := binary.Read(dataBuff, binary.LittleEndian, &ctx)
if err != nil {
panic(err)
}
switch ctx.Type {
case DataArg:
if _, ok := events[ctx.Tid]; !ok {
events[ctx.Tid] = &Event{
Ts: ctx.Ts,
Pid: ctx.Pid,
Tid: ctx.Tid,
Uid: ctx.Uid,
Comm: string(ctx.Comm[:]),
Args: []string{dataBuff.String()},
}
} else {
events[ctx.Tid].Args = append(events[ctx.Tid].Args, dataBuff.String())
}
case DataEnv:
if _, ok := events[ctx.Tid]; ok {
events[ctx.Tid].Envs = append(events[ctx.Tid].Envs, dataBuff.String())
}
case DataRet:
if _, ok := events[ctx.Tid]; ok {
events[ctx.Tid].Ret = ctx.Ret
s.eventsChanOut <- events[ctx.Tid]
delete(events, ctx.Tid)
}
}
select {
case <-done:
return
default:
break
}
}
}
运行用户态程序
万事俱备,现在我们可以来运行用户态程序了:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
func (s *Snoopy) Run() {
sig := make(chan os.Signal, 1)
signal.Notify(sig, os.Interrupt)
s.execvePerfMap.Start()
s.execveatPerfMap.Start()
done := make(chan struct{})
s.eventsChanOut = make(chan *Event, 128)
go s.handler(s.execveDataChan, done)
go s.handler(s.execveatDataChan, done)
go s.printer(done)
<-sig
close(done)
s.execvePerfMap.Stop()
s.execveatPerfMap.Stop()
s.bpfModule.Close()
}
其中,PerfMap的Start方法开启了一个新的协程不断调用libbpf的perf_buffer__poll API进行轮询:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
func (pb *PerfBuffer) poll() error {
defer pb.wg.Done()
for {
select {
case <-pb.stop:
return nil
default:
err := C.perf_buffer__poll(pb.pb, 300)
if err < 0 {
if syscall.Errno(-err) == syscall.EINTR {
continue
}
return fmt.Errorf("error polling perf buffer: %d", err)
}
}
}
}
为了提供更友好的用户接口,我们可以用github.com/urfave/cli/v2包封装一个命令行程序。
完整代码仓库
限于篇幅,本文没有阐述基于libbpfgo的用户态程序和eBPF程序的编译流程,感兴趣的读者可前去本文的代码仓库查看Makefile。
本文的全部代码可在我的GitHub代码仓库中查看:Snoopy-eBPF: Catching Program Executions with eBPF
欢迎提出各类宝贵的修改意见和issues,指出其中的错误和不足!
最后,感谢你读到这里,希望我们都有所收获!