在实现完简单的Reactor编程框架后,我们可以进一步扩展,使其效率更高、更加强劲。
扩展Reactor框架
引入Buffer
在之前实现的TcpConnection中,receive和send相关方法都是直接与文件描述符直接交互的。虽然事件通知时,文件描述符对应的读写资源都是准备就绪的,此时对其读写不会因为等待I/O资源长时间阻塞。但我们也有主动在连接上发起读写请求的时候,此时我们的行为不是基于事件通知的。
在我们主动进行I/O时,我们如何判断资源是否就绪呢?如果资源没有就绪,而我们就进行I/O,很可能让进程陷入等待。我们可以把文件描述符设置为非阻塞的,然后尝试I/O,如果有报错,说明当前资源没有完全准备好。
这时,我们希望利用我们的事件通知机制,在资源准备好时,继续进行I/O操作,相当于我们将自己的主动I/O请求“托管”给了框架。
为了达到这一目的,我们要引入新的抽象层Buffer,将我们的数据先复制到Buffer中,由框架在时机成熟时,读写Buffer完成我们的主动I/O请求。同时,修改相关Channel的写回调函数。
1
2
3
4
5
6
7
8
9
10
vector<ChannelOp> handle_connection_write() {
cout << "ConnectionChannel: handle_connection_write\n";
conn.buffer_send();
if (conn.buffer_in.eof()) {
if (write_completed_callback != nullptr) {
write_completed_callback(conn);
}
}
return {};
}
再谈边缘触发与条件触发
如果我们将所有的写事件都交给框架处理,会遇到一个尴尬的情况:对于conn_fd而言,往往在等待客户端的请求(读事件),但写事件一直是就绪的。我们只有在Buffer中有数据时,才会真正向conn_fd写入数据。然而此时,Buffer中没有数据时,也会收到来自Dispatcher的conn_fd可写的通知。过多的重复(且无效的)通知会大大拖慢系统的性能。
如果我们开启边缘触发,这种性能损耗就会得到缓解。由于我们没有数据可写,因此并没有对conn_fd的写事件作出响应,下一次基于边缘触发的Dispatcher就不会通知了。
当然,这会带来新的问题,即当我们稍后主动向Buffer中写数据时,很可能会面临收不到Dispatcher的写事件通知的情况,这是灾难性的,因为对于基于事件驱动的框架来说,要收到有写事件通知才会触发写入conn_fd的行为。通常,要等到有客户端请求发来时才会再次收到写事件的通知,该通知是和conn_fd的读事件一起发过来的。
因此,当我们有主动写conn_fd的需求时,最好的方式是先尝试直接对其写入。若发现写入失败,再向Dispatcher注册conn_fd的写事件,并且在写入完全完成后,注销该事件。这种实现下,即使不开启边缘触发,或是使用poll,也会有较好的性能。为方便简洁起见,本文的代码并没有实现这种机制,有兴趣的读者可以尝试实现一下。
分发事件的错误方式
基于事件驱动的好处之一是可扩展性好,我们可以很方便地将其扩展为多线程的程序。如下图所示,我们只需要将事件发送到一个任务队列中,然后创建一个线程池,让不同的线程从任务队列中取出事件通知,各自响应事件即可。
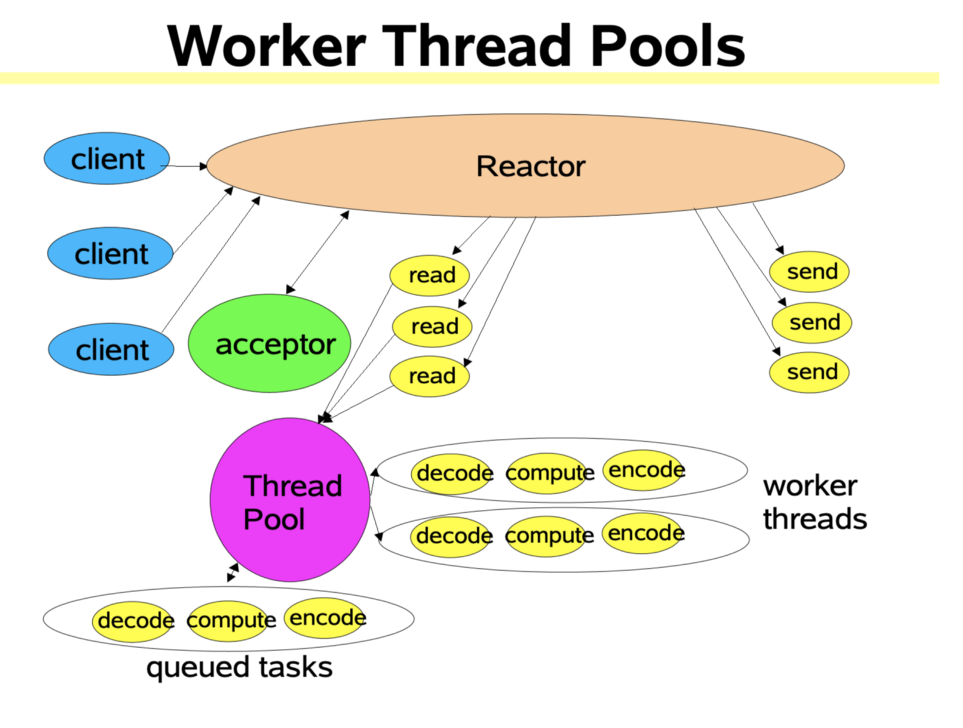 多线程的Reactor模式1
多线程的Reactor模式1
这种事件通知与分发机制十分好理解,也是行之有效的多线程分工方式。那么,该如何实现呢?
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
void worker() {
// ...
while (true) {
auto channel = work_queue.try_pop();
channel->on_event(channel->revents);
}
}
int main() {
// ...
while (true) {
vector<DispatcherEvent> events{dispatcher->dispatch()};
for (auto &event : events) {
Channel *channel = channel_map[event.fd].get();
work_queue.push(channel);
}
}
}
假设我们使用了上面的实现方式,主线程不断查询事件,并把要处理的Channel放入work_queue中,而子线程每次只需要简单地从中取出一个Channel,调用on_event即可(你可以假设on_event返回的结果在稍后也通过阻塞队列的方式返回给主线程)。你是否能看出有什么问题?
是的,这样的线程协作方式是错误的。原因在于主线程和工作线程的步调不一致,很可能工作线程还没有完成on_event的处理,而主线程已经开始下一次的dispatch了。这会导致事件被重复通知并放入work_queue里,这显然是错误的。
简单的多线程实现
我们给出一个简单的多线程Reactor框架实现。每个工作线程都维护自己的channel_map和dispatcher,主线程只负责acceptor的连接监听,work_queue中存放ChannelOp。如此一来,工作线程根据ChannelOp创建ConnectionChannel,在同一个线程中处理来自相同用户的后续请求。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
void worker(const string &name, block_queue<ChannelOp> &work_queue) {
unordered_map<int, unique_ptr<Channel>> channel_map;
unique_ptr<Dispatcher> dispatcher{new EpollDispatcher()};
while (true) {
auto conn_op = work_queue.try_pop();
if (conn_op.has_value()) {
cout << "hi\n";
assert(conn_op->op == CHANNEL_ADD);
assert(conn_op->channel_type == CHANNEL_CONN);
auto *channel = new ConnectionChannel(conn_op->fd);
channel->message_callback = on_message;
channel->connection_closed_callback = on_connection_closed;
dispatcher->add(channel);
channel_map[conn_op->fd] = unique_ptr<Channel>(channel);
cout << "[worker " << name << "] new connection established: fd=" << conn_op->fd << endl;
}
vector<DispatcherEvent> events = move(dispatcher->dispatch());
for (auto &event : events) {
if (!channel_map.count(event.fd)) {
continue;
}
Channel *channel = channel_map[event.fd].get();
vector<ChannelOp> channel_ops{channel->on_event(event.revents)};
cout << "[worker " << name << "] handle event\n";
for (auto &op : channel_ops) {
assert(op.op == CHANNEL_REMOVE);
Channel *channel = channel_map[op.fd].get();
dispatcher->remove(channel);
channel_map.erase(op.fd);
close(op.fd);
cout << "[worker " << name << "] remove conn fd=" << op.fd << endl;
}
}
}
}
int main() {
block_queue<ChannelOp> work_queue;
unique_ptr<Dispatcher> dispatcher{new EpollDispatcher()};
unique_ptr<Channel> acceptor{new AcceptorChannel(8888)};
dispatcher->add(acceptor.get());
thread worker1{worker, "1", ref(work_queue)};
thread worker2{worker, "2", ref(work_queue)};
while (true) {
vector<DispatcherEvent> events = move(dispatcher->dispatch());
for (auto &event : events) {
vector<ChannelOp> channel_ops{acceptor->on_event(event.revents)};
for (auto &op : channel_ops) {
cout << "push op\n";
work_queue.push(op);
}
}
}
return 0;
}
还能做什么?
封装EventLoop和线程池
实际上,我们的main函数和worker工作线程都是一个无限循环,这个无限循环尤其自身要管理的状态,即dispatcher和channel_map(main函数中值管理一个AcceptorChannel,因此被省略了)。我们可以对线程的行为进行封装,不同的线程对应不同的EventLoop实例,并且在此基础上抽象出线程池类。
提供更高层的接口
基于上面所说的扩展,我们可以封装出更高层的接口,如TcpServer。用户在使用时,只需要指定TcpServer的一些回调函数以及需要的线程池大小,就可以调用TcpServer的start方法开始对外提供服务。为了将项目代码控制在一个简洁易读的规模,我们没有引入EventLoop和TcpServer这些额外的抽象层次。
此外,我们可以提供常用的回调函数实现,例如与HTTP服务相关的回调函数,从而实现一个HttpServer。
完整代码仓库
「网络编程101」系列全部代码可在我的GitHub代码仓库中查看:Captor: An easy-to-understand Reactor in C++
欢迎提出各类宝贵的修改意见和issues,指出其中的错误和不足!
最后,感谢你读到这里,希望我们都有所收获!