之前我们在编写Reactor网络编程框架时,已经简单介绍了几种典型的Linux I/O模型,在本文中,我们将对这些模型进行简单梳理总结,介绍它们的用法和优缺点。
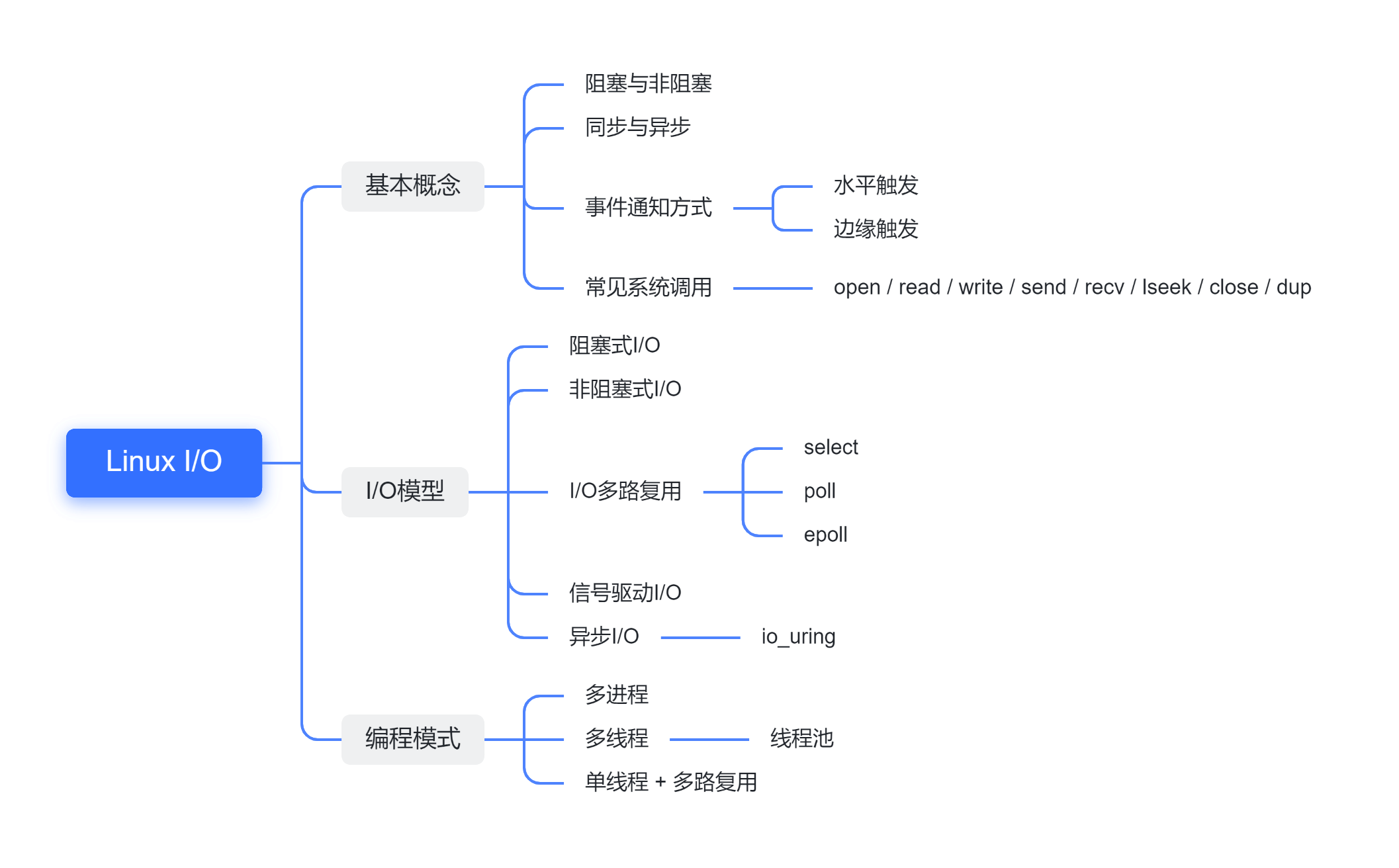 本文结构
本文结构
基本概念
阻塞与非阻塞、同步与异步往往被混为一谈。这在一些语境下是可以不作严格区分的,例如多线程编程时,一个线程向另一个线程下达了任务,自己转而执行别的工作。之后,它将以轮询或事件通知的形式得知自己提交的任务是否被完成。由于该线程在等待其它人完成任务时,自己可以腾出手做别的事情,因此这个过程调用是“非阻塞的”。在收到事件通知后再进一步处理,所以该过程同时也是“异步”的。
不过,在Linux I/O的语境下,这两个概念需要有一定的区分。接下来,我们来简单介绍一下。
阻塞与非阻塞
阻塞和非阻塞针对系统调用的执行方式。
阻塞调用
在进程发起I/O系统调用后,若条件未准备充分(如读取的socket上没有数据、写入的缓冲区已满等),进程将被操作系统挂起,陷入阻塞状态。内核转而调度其它进程,充分利用CPU资源,这符合操作系统应当高效管理和利用系统资源的设计目标。当时机成熟后,原有的进程重新进入调度队列,等待被内核唤醒。这一流程类似多线程中条件变量的效果。
非阻塞调用
非阻塞调用将选择权还给进程。当I/O请求的数据未准备完成时,系统调用会返回一个错误码。进程此时可以选择先去做其它事,稍后以轮询的方式再次发起I/O请求。当然,所谓“权利越大,责任越大”,进程有了不被阻塞的权利,也应当考虑如何充分利用CPU资源。如果采用在一个循环体中不断询问I/O请求是否就绪的方式编程,这将让CPU浪费在执行无用的循环上,而对进程而言,处理I/O事件的效率与阻塞调用相比相差不大。
同步与异步
同步和异步针对数据在用户态和内核态之间传输的方式。
同步调用
当数据准备完成后,用户态与内核间的数据传输才正式开始。采用同步调用时,进程会一直等待I/O操作完成,再执行下一条语句。要注意的是,“等待”并不意味着“阻塞”,因为此时数据以及准备充分,操作系统不会将进程挂起。进程要做的仅仅是等待函数调用执行完毕,即等待复制过程结束。值得注意的是,一般的read和write的数据传输都是同步的。
异步调用
异步调用通常是非阻塞的,相当于向商家下达了一份订单,商家将商品送到门口后会敲门通知你订单已完成。发起异步I/O后,进程可以转而处理其它事情,在此过程中等待“送货上门”。送完货后,进程可以直接从缓冲区中取货。如果将这个比喻用在同步调用上,那么它们的区别体现在同步调用更像是“自提”的模式,在商品准备好后,需要再额外麻烦一下,外出将货物取回自己的缓冲区中。
事件通知方式
Linux I/O事件通知有两种形式:水平触发(level-triggered)和边缘触发(edge-triggered)。
水平触发
只要当前文件描述符是可读/可写的,就发送事件通知。可读/可写的含义是进程对其I/O时不会阻塞。水平触发是一种“保守”的通知方式,它保证进程不会错过文件的读写事件。如果进程在I/O进行到一半时再次查询,仍然会被通知该描述符是就绪状态,直到本次I/O结束,即没有数据可读/可写。
边缘触发
仅当文件描述符自上次查询以来有了新的I/O活动(或是首次查询)时才触发通知。边缘触发拥有较好的性能,因为同一I/O就绪状态不会被反复通知。在进行下一次查询时,可能上一次查询中返回的I/O事件还没有被进程完全处理完毕,在这样的场景中,边缘触发可以避免同一个事件被多次处理,同时也避免排在后面的文件描述符“饥饿”的情况。
边缘触发通常与非阻塞I/O联合使用,因为其通知机制限制,要求进程在收到事件通知时尽可能多地读写文件。否则,若仅进行了部分读写,很可能由于文件描述符没有新的事件到来而无法产生事件通知,最终错过剩余的数据。为了达到“尽可能多读写”的目的,由于不知道还剩多少数据未处理,在编程时通常要使用一个循环不断地对文件发起读写,并检查返回的错误码是否提示数据已经读写完毕。如果使用了阻塞I/O,此时在循环体中最后一次I/O时会被阻塞,影响进程的正常执行。
I/O模型
一般认为Linux的I/O模型有5种:
- 阻塞式I/O
- 非阻塞式I/O
- I/O多路复用
- 信号驱动I/O
- 异步I/O
其中,阻塞与非阻塞I/O是最朴素的I/O形式,很容易理解。经常讨论的则是I/O多路复用,它可以与阻塞和非阻塞结合。常用的多路复用函数有select、poll和epoll。其中,poll可以认为是select的升级版,打破了select的一些限制,但它们底层实现一致,因此多数情况它们的性能接近。epoll则有远超它们的性能,成为Redis这样单线程模型的高性能杀手锏。信号驱动I/O也有不错的性能,它的通知方式相当于边缘触发。异步I/O曾经只有较为“简陋”的接口,但在新的Linux内核中出现了更强大的io_uring,有望改变epoll一统天下的格局。
I/O多路复用
在普通的读写文件场景,通常I/O开销是很小的。但如果进程同时要处理多个I/O请求,例如一方面要接受网络请求,另一方面又要接收用户在终端中的输入,那么等待I/O就变得十分昂贵。如果阻塞在等待用户输入上,进程将无法服务来自网络的请求。为了尽可能利用CPU资源,我们可以借助I/O多路复用技术,通过向内核注册要监听的文件描述符,让内核查询并返回就绪的I/O资源,然后在用户态处理。常用的I/O多路复用函数包括select、poll和epoll。
select
select1的定义在sys/select.h中:
1
2
3
4
5
6
7
8
9
10
#include <sys/select.h>
int select(int nfds, fd_set *restrict readfds,
fd_set *restrict writefds, fd_set *restrict exceptfds,
struct timeval *restrict timeout);
void FD_CLR(int fd, fd_set *set);
int FD_ISSET(int fd, fd_set *set);
void FD_SET(int fd, fd_set *set);
void FD_ZERO(fd_set *set);
在Linux手册中我们可以找到select函数的参数定义。我们用fd_set与select交互,设置该结构体,通知select我们要监听的文件描述符和事件。使用FD_*函数对结构体赋值和字段查询。select参数具体含义如下:
nfds:要监控的文件描述符中最大值+1,不能超过1024;readfds、writefds、exceptfds:表示要监听描述符上的三类事件,即描述符可读、可写、发生异常;timeout:超时时间,单位微秒。
fd_set其实就是一个long int类型的位图数组,一共有32个32位的元素,因此select只能监听0到1023号文件描述符(共1024个)。许多文章里都只说明select只能监听1024个文件描述符,往往会给人错觉,认为超过1024个文件描述符时可以多次调用select,每次传入不同的fd_set解决这一问题,但实际上nfds超过1024时,select会返回-1,且nfds是根据fd_set中最大的文件描述符号确定的。
select函数的查询结果是通过传入的指针参数返回的,因此,用户传入的readfds等fd_set会被改变。用户若下一次仍想查询同样的文件描述符,需要重新设置fd_set。
poll
poll与select类似,但突破了最多监听到1023号文件描述符的限制,定义如下:
1
2
3
4
5
6
7
8
9
#include <poll.h>
int poll(struct pollfd *fds, nfds_t nfds, int timeout);
struct pollfd {
int fd; /* file descriptor */
short events; /* requested events */
short revents; /* returned events */
};
与poll打交道的结构体为pollfd,fds数组在内核中会以链表形式存储,因此没有文件描述符数量上的限制。此外,与select一样,poll的查询结果通过指针返回,但内核返回的事件会存放在revents中,不会修改用户的查询参数。因此,用户态程序在发起下一次查询时无须再重新设置pollfd数组,相比select有了进步。
epoll
无论是select还是poll,内核在查询文件描述符就绪状态的复杂度都是O(nfds)的,即发起调用后内核总是要逐个检查这些文件描述符的状态。在监听的文件描述符过多时,开销无法忽略。
epoll的出现就是为了解决这一问题。用户通过epoll_ctl注册要监听的事件,这些事件将一直维护在内核中,不需要每次查询都传入事件参数。此外,epoll会注册相应的回调函数(callback),当文件描述符状态变化时,回调函数会将该文件描述符放入就绪队列中。在用epoll_wait查询时,内核直接返回就绪队列中的元素,复杂度为O(1)。此外,这一机制也很方便地让epoll支持了边缘触发的通知机制,select和poll仅支持水平触发。
用户可以使用epoll_create创建epoll实例,用epoll_ctl对感兴趣的文件描述符及其事件进行增删和修改,使用epoll_wait发起I/O就绪事件查询。为了高效实现内核中文件描述符节点的增删改查,epoll实现时使用了红黑树。此外,就绪队列的实现也直接基于红黑树的节点。
对epoll的具体使用方式感兴趣的读者可以参考我以前的文章或是查询Linux文档2。
对比
select与poll:
- 底层实现都基于同一套内核的文件描述符状态查询逻辑;
- timeout精度:
select精度更高,为微秒;poll为毫秒; - 文件描述符约束:
poll没有限制,select仅支持0-1023; - 查询结果返回方式:
select会修改传入的fd_set,而poll使用传入参数中的revents,使用时更方便; - 错误处理:文件描述符被关闭时,
select返回返回错误,但无法定位到是fd_set中的哪个文件被关闭了;poll则会在被关闭的文件描述符的revents中设置POLLNVAL事件; - 性能上:早期版本的
select对于文件描述符集合“稀疏”的场景性能(如查询的两个文件描述符号为3和1000)较差,poll则没有问题。新的版本中弥补了这一差距。
与epoll:
- 文件类型:
select与poll支持普通文件(regular file)的读写事件监听,且总是返回就绪,因为不同于socket,文件I/O总是在有限时间内可以返回。epoll则不支持普通文件; - 系统调用传递参数大小:
epoll_wait传入的参数少,无须每次调用都传入fd_set这样查询集合,意味着从用户态复制到内核态的数据最少,系统调用开销小; - 通知方式:
epoll相比select和poll,额外提供了边缘触发方式; - 具体实现:
epoll在内核中维护了进程感兴趣的I/O事件,以红黑树方式高效组织。注册回调函数,维护就绪事件列表,达到查询O(1)复杂度。select和poll对于I/O事件的多路复用则是一次性的,进程每次轮询都需要它们进行许多重复劳动。
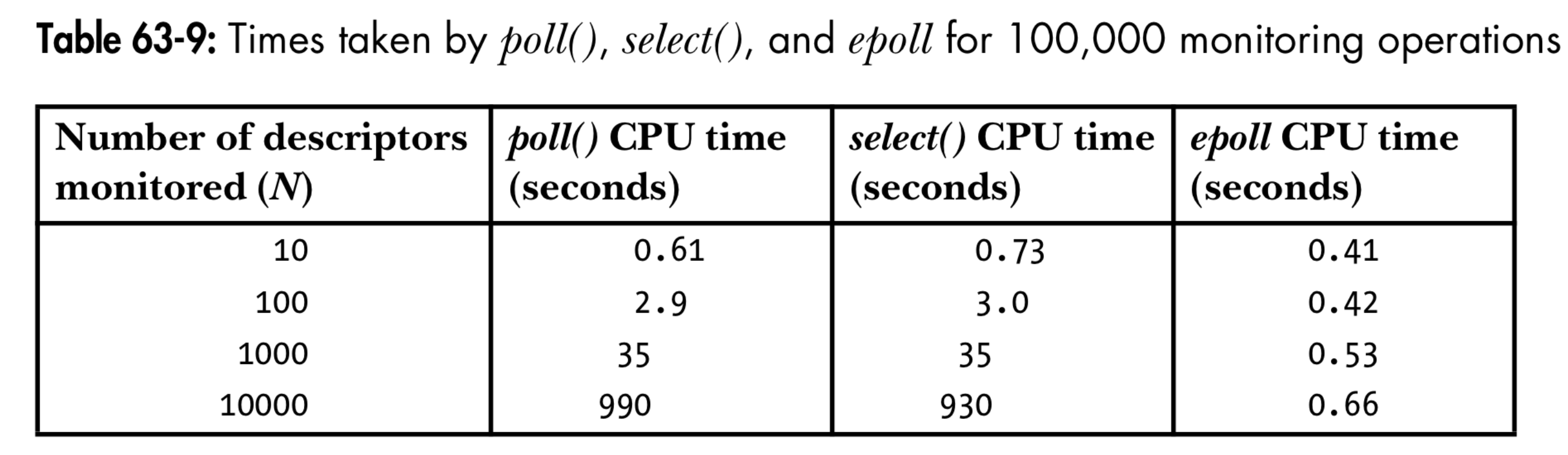
select、poll和epoll性能对比3
信号驱动I/O
信号驱动I/O免去了I/O多路复用中需要进程轮询的过程,内核在检测到可读可写事件后,执行进程的信号处理程序,在其中可以处理文件读写。但值得注意的是,从根本上讲,进程依然无法避免轮询,因为主程序需要判断自己是否已经完成了I/O请求,好进行后续逻辑,这通常基于信号处理程序在完成I/O后设置的一些全局状态。
信号驱动I/O是边缘触发的,因此也需要将文件描述符设置为非阻塞的,内核在发送信号后尽可能多地进行I/O操作。信号处理是阻塞式的,即当我们在执行信号处理函数时,若有新的信号产生,将不会被发送。此外,需要注意的是信号的发送是不会积累的,在阻塞时,若信号产生了多次,这些信号最后只会被发送1次。
信号驱动I/O通常不会用于TCP套接字的读写,因为有许多事件都会触发信号,且我们无法区分触发当前信号的具体事件是哪个。在UDP编程中有使用信号驱动I/O的实例,有兴趣的读者可以去进一步探究。
异步I/O大杀器:io_uring
Linux曾经对于异步I/O的支持是有限的,最初只支持使用O_DIRECT模式的文件描述符,该模式下Linux不会管理I/O缓冲区,往往是为了数据库这类自行管理文件页面缓冲的软件准备的。注意区分Linux内核提供的异步I/O与glibc提供的用户层POSIX aio接口的区别,aio基于多线程实现4,个人认为其与内核的异步I/O有一定区别,并非真正的“异步I/O”。更多与内核异步I/O有关的可以参考这个代码仓库(linux-aio 5),以及内核文档67。
目前,Linux社区已经在提供新的异步I/O能力:io_uring 8。与最初的内核异步I/O相比,io_uring支持的文件类型更多,适用更多场景。与同步I/O相比,基于内核的异步I/O接口极大地节省了进程的CPU资源。io_uring提供了两个进程和内核共享的队列:提交队列(submission queue, SQ)和完成队列(completion queue, CQ)。进程只需要向队列提交I/O请求即可,提交的过程开销忽略不计。内核会自动把完成的请求放入完成队列,若是读请求,读出的数据也会一并放提交任务时指定的缓冲区里,无须进程再次调用read自行读取,这也是同步和异步的本质区别。此外,进程可以选择一次性提交多个I/O请求,达到一次系统调用通知多个请求的目的,批量化以节省昂贵的系统调用次数。下图展示了io_uring的基本组成,可以看到,两个队列,一入一出,形成了一个环(ring),且这些队列是用户态与内核共享的,存在于用户态(userspace),这也就是uring的含义。
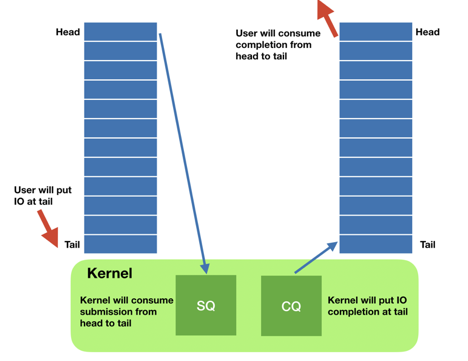 io_uring9
io_uring9
在一些网上的benchmark中,可以看到io_uring的效率高于epoll。效率提升只是io_uring的好处之一,它的另一个杀手特性是可编程性。之前我们已经介绍过eBPF,它允许用户在内核中挂载用户的eBPF程序代码片段,由eBPF虚拟机执行。eBPF的出现使得对内核的编程更友好、更安全。io_uring允许用户挂载eBPF程序10,对应程序类型为BPF_PROG_TYPE_IOURING,使用bpf系统调用,传入IORING_ATTACH_BPF指令进行挂载。这样一来,相当于对io_uring增加了回调函数,在有异步I/O事件完成时,我们可以直接在内核态的eBPF函数中进行下一步处理。
虽然系统调用中已经有io_uring的调用号,但Linux没有直接提供函数接口。liburing提供了对io_uring的封装,同时也为我们考虑了读写屏障等细节,极大地方便了我们的编程。io_uring和liburing正在演进中11,随着内核的更新会加入更多性能特性、支持更多操作类型,相信在不久后我们会看到特性和性能稳定成熟的版本。
我写了一个基于io_uring的简易TCP服务器,有兴趣的读者可以去代码仓查看:io-uring-tcp-server 12。